RAPID: 长上下文推理的检索增强推测解码
论文摘要
大型语言模型(LLM)的最新进展使得直接处理百万词文档成为可能,这为传统的检索增强生成(RAG)提供了一种有前景的替代方案。然而,长上下文推理的计算开销带来了显著的效率挑战。传统的推测解码(SD)使用较小的草稿模型来加速推理,但其有效性在长上下文场景中会大幅下降,因为内存受限的键值(KV)缓存操作。我们提出检索增强推测解码(RAPID),该方法将RAG的效率与SD的加速优势相结合。RAPID引入RAG草稿模型——一个在检索到的精简上下文上运行的草稿LLM——来推测长上下文目标LLM的生成。我们的方法开辟了一个新范式,使得同规模甚至更大的LLM可以作为RAG草稿模型来加速较小的目标LLM,同时保持计算效率。为了充分利用来自更强RAG草稿模型的潜在优势,我们开发了一种推理时知识转移机制,通过RAG丰富目标分布。在LLaMA-3.1和Qwen2.5系列模型上的广泛实验表明,RAPID有效地整合了RAG和长上下文LLM的优势,实现了显著的性能提升(例如,LLaMA-3.1-8B在InfiniteBench上从39.33提升到42.83),同时长上下文推理实现了超过2倍的加速。我们的分析还表明,RAPID在各种上下文长度和检索质量下都表现出强大的鲁棒性。
基本信息
| 项目 | 内容 |
|---|---|
| 论文ID | 2502.20330 |
| 标题 | RAPID: Long-Context Inference with Retrieval-Augmented Speculative Decoding |
| 中文标题 | RAPID:长上下文推理的检索增强推测解码 |
| 作者 | Guanzheng Chen, Qilong Feng, Jinjie Ni, Xin Li, Michael Qizhe Shieh |
| 单位 | National University of Singapore (新加坡国立大学), DAMO Academy, Alibaba Group (阿里巴巴达摩院), Hupan Lab (湖畔实验室) |
| 会议 | ICML 2025 |
| arXiv ID | 2502.20330 |
| 代码链接 | https://github.com/NUS-TRAIL/RAPID |
| 日期 | 2025年2月 |
1. 引言
1.1 背景与动机
大型语言模型(LLM)传统上依赖检索增强生成(RAG)来处理广泛文档,通过选择性检索相关文本片段。虽然有效,但RAG的性能本质上受限于检索器在不同查询中提取相关信息的能力。最近出现的长上下文LLM能够直接处理百万词文档,这为复杂的RAG流程提供了一种有前景的替代方案。然而,这一突破受到长上下文推理计算效率的瓶颈制约,因为处理广泛的键值(KV)缓存成为内存受限的操作,并引入大量延迟。
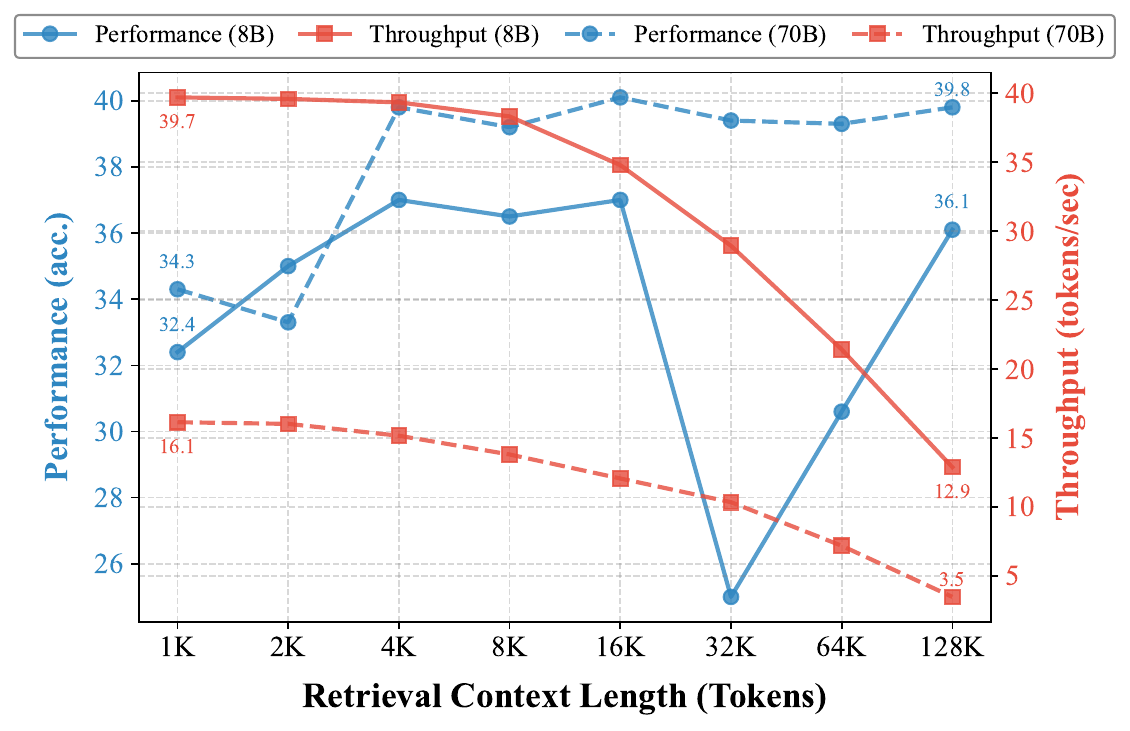
推测解码(SD)是加速LLM推理的一种流行方法,通过利用较小的草稿模型提出多个候选token,供目标模型在单次前向传播中进行验证。SD的优势取决于两个关键因素:草稿模型生成候选token的计算效率,以及其产生高质量可接受候选的能力。然而,在长上下文场景中,SD的有效性会降低,因为内存受限的KV缓存操作阻止了较小的LLM保持相对于较大模型的显著速度优势。如图1所示,LLaMA-3.1-8B相对于LLaMA-3.1-70B的吞吐量增益随着上下文长度从1K增加到128K token而急剧下降(23.6 → 9.4)。
1.2 核心贡献
我们引入检索增强推测解码(RAPID),以弥补SD在加速长上下文推理方面的差距,同时提升生成质量。RAPID采用RAG草稿模型——一个在RAG检索到的精简上下文上运行的草稿LLM——按照SD流程来推测长上下文LLM的生成。我们提出RAG草稿模型可以作为长上下文目标LLM的理想草稿模型,因为它展现出接近长上下文LLM能力的潜力,同时提供更优的计算效率。如图1所示,LLaMA-3.1-8B配合RAG在4K~16K token上可以恢复使用完整128K token实现的大部分性能。这表明RAG草稿模型能够为长上下文目标LLM生成具有高接受率的高质量候选token,同时消除长上下文上的内存受限KV缓存操作以加速推理过程。
此外,我们的RAPID为SD开辟了一个新范式,即利用同规模甚至更大的LLM作为RAG草稿模型来加速较小的目标LLM。这种范式转变是可能的,因为RAG草稿模型在精简上下文上运行(例如4K),可能比同规模甚至更大规模的目标LLM在长上下文上(例如128K)保持更高的效率。
1.3 检索增强目标分布
然而,原始SD使用目标LLM预测作为真实分布进行拒绝采样,可能会忽略来自更强RAG草稿模型的高质量候选。这将导致对有效候选的不必要拒绝,从而阻碍效率和性能提升。
为解决这一限制,RAPID实现了一种检索增强目标分布,将SD中原始长上下文目标分布与推理时知识转移相结合。具体而言,我们反向将RAG草稿模型定位为教师,长上下文目标LLM定位为学生,以在推理过程中获得朝向RAG草稿模型的蒸馏logit偏移。通过将该偏移纳入目标LLM的预测logit,我们获得了一个更易于接受高质量推测候选的增强目标分布。
2. 方法
2.1 背景:推测解码
使用LLM $p_\phi$的自回归生成传统上需要顺序的前向传播,其中每个token $x_i$从分布 $p_\phi(x_i | x_{<i})$ 中采样。这种顺序性质因GPU DRAM中LLM参数加载和KV缓存操作而产生大量计算开销。
SD通过使用较小的草稿模型 $q_\psi$ 生成$\gamma$个候选token来加速这一过程,然后通过拒绝采样在单次前向传播中由目标模型 $p_\phi$ 验证。对于每个推测token $x^{\prime}_i \sim q_\psi(x_i | x_{<i})$,接受标准为:
$$r \leq \min\left(1, \frac{p_\phi(x^{\prime}_i| x_{<i})}{q_\psi(x^{\prime}_i| x_{<i})}\right)$$其中 $r \sim U(0,1)$。当被拒绝时,从残差分布中采样新token:
$$x_i \sim \texttt{norm}({\max(p_\phi(x_i|x_{<i}) - q_\psi(x_i|x_{<i}), 0)})$$该程序保证重采样的token遵循与直接从目标模型 $p_\phi$ 采样相同的分布,同时在推测token被接受时可能实现显著加速。
2.2 概述
传统SD为标准长度上下文提供显著加速,但在处理广泛文档时由于内存受限的KV缓存操作而其优势大幅减少。我们提出RAPID,一种为长上下文场景重新思考SD同时提升生成质量的方法。如算法1所示,RAPID包含两个关键组件:
RAG草稿模型:SD在长上下文上变得低效,因为草稿和目标LLM都必须在内存中处理完整上下文,抵消了较小草稿模型的计算优势。为克服这一挑战,RAPID利用RAG草稿模型为目标LLM生成候选。RAG草稿模型在选择性检索的上下文片段上运行,能够在保持相关信息访问的同时实现显著加速。
检索增强目标分布:SD中的严格接受标准可能会拒绝高质量候选,因为它要求与目标LLM分布严格匹配才能接受。当使用RAG草稿模型时,这一限制变得尤为明显,因为在某些场景下RAG可能产生比长上下文LLM更高质量的输出。为整合来自RAG草稿模型的优势,RAPID采用检索增强目标分布,实现从RAG草稿模型到目标模型在推理时的知识转移。
2.3 RAG草稿模型
当处理广泛上下文 $\mathcal{C}$ 的查询时,朴素SD的目标分布为:
$$p(x_i) = p_\phi(x_i \vert [\mathcal{C};x_{<i}])$$即使使用较小的草稿模型,由于对完整上下文 $\mathcal{C}$ 进行内存受限的KV缓存操作,计算优势也会大幅减少。
为克服这一限制,我们建议利用RAG作为草稿模型的基础。与处理完整上下文 $\mathcal{C}$ 不同,我们的RAG草稿模型在压缩上下文 $\mathcal{C^{\text{S}}}$ 上运行。具体而言,$\mathcal{C^{\text{S}}}$ 通过选择性检索构建:将 $\mathcal{C}$ 中的文本片段编码到密集向量空间,其中语义相似性通过与查询的余弦相似度来衡量,从而实现最相关上下文块的高效识别和提取。
在获得压缩上下文 $\mathcal{C^{\text{S}}}$ 后,草稿分布正式定义为:
$$q(x_i) = q_\psi(x_i \vert [\mathcal{C^{\text{S}}};x_{<i}])$$其中我们通过强制执行 $|\mathcal{C^{\text{S}}}| \le |\mathcal{C}|/\lambda$ 且 $\lambda \gg 1$ 来严格控制压缩比。这个压缩上下文使我们的草稿模型能够保持显著的速度优势,同时保留对相关信息的访问。
基于RAG草稿模型,修改后的推测解码过程如下。对于每个生成步骤,我们从RAG草稿模型采样$\gamma$个推测token作为 $x^{\prime}_i \sim q(x_i)$。这些候选使用修改后的接受标准针对目标模型进行验证:
$$r \leq \min\left(1, \frac{p(x_i)}{q(x_i)}\right) = \min\left(1, \frac{p_\phi(x^{\prime}_i| [\mathcal{C};x_{<i}])}{q_\psi(x^{\prime}_i| [\mathcal{C^{\text{S}}};x_{<i}])}\right)$$其中 $r \sim U(0,1)$。
RAG草稿机制提供两个关键优势:(1)通过压缩上下文操作显著减少内存开销和计算成本($|\mathcal{C^{\text{S}}}| \ll |\mathcal{C}|$),(2)通过选择性检索相关信息可能增强推测质量,相比处理稀释的完整上下文。此外,由于在缩短上下文上的显著效率,RAPID甚至可以使用同规模或更大的模型作为草稿模型来加速较小的目标LLM。
2.4 检索增强目标分布
LLM有效利用上下文的能力通常会随着无关信息的包含而下降。我们 empirical analysis in Figure 1 shows that LLMs,通过聚焦检索到的相关块,有时可以超越完整上下文的生成质量。然而,朴素SD的严格接受标准可能导致对这些优越生成的不必要拒绝,当它们偏离目标分布时,这会导致质量下降和计算效率低下。
为解决这一限制,我们引入检索增强目标分布,实现从RAG草稿模型到长上下文目标模型在推理时的知识转移。形式上,RAPID中的检索增强目标分布定义为:
$$\hat{p}(x_i) = \softmax(z(x_i) / T + \eta \cdot (q(x_i) - p(x_i)))$$其中 $\eta$ 是控制知识转移强度的超参数,$z(x_i)$ 是目标LLM的未归一化logit,即 $p(x_i) = \softmax \left(z(x_i)/T\right)$,$T$ 是温度。
命题1:设 $p(x) = \softmax(z(x)/T)$ 是由logit $z(x)$ 和温度 $T$ 参数化的学生模型分布,$q(x)$ 是教师模型分布。知识蒸馏损失 $\mathcal{L} = T^2 \cdot \text{KL}(q(x) \| p(x))$ 相对于 $z(x)$ 的梯度为:
$$\frac{\partial \mathcal{L}}{\partial z(x)} = T \cdot (p(x) - q(x))$$检索增强目标分布的设计意味着一个知识蒸馏步骤,通过将RAG草稿模型定位为教师,目标模型定位为学生,将RAG草稿模型的一部分知识注入朴素的长上下文目标分布。
具体而言,对于RAG草稿分布 $q(x_i)$(教师)和长上下文目标分布 $p(x_i)$(学生)之间的蒸馏损失 $\mathcal{L}$,根据命题1,我们有蒸馏logit偏移:
$$\frac{\partial \mathcal{L}}{\partial z(x_i)} = T \cdot (p(x_i) - q(x_i))$$现在我们可以通过以下方式获得由RAG草稿模型增强的"蒸馏" $z(x_i)$:
$$\hat{z}(x_i) = z(x_i) - \eta \frac{\partial \mathcal{L}}{\partial z(x_i)} = z(x_i) + \eta T(q(x_i) - p(x_i))$$其中 $\eta$ 控制知识转移的强度。因此,公式(4)中的检索增强目标分布等同于归一化的 $\hat{z}(x_i)$,即 $\hat{p}(x_i) = \softmax(\hat{z}(x_i)/T)$。
检索增强目标分布 $\hat{p}(x_i)$ 能够在保持验证能力的同时实现从RAG草稿模型的灵活知识转移。由于未归一化logit $z(x_i) \in \mathbb{R}$ 与归一化分布 $p(x_i), q(x_i) \in [0,1]$ 相比具有更大的幅度,$\hat{p}(x_i)$ 保留了目标LLM有效验证候选的长上下文能力。
对于推理,我们将公式(5)中的 $p(x_i)$ 替换为 $\hat{p}(x_i)$。设 $p(x_i) = [\ervw_j]_{j=1}^{|V|}$ 和 $\hat{p}(x_i) = [\hat{\ervw}_j]_{j=1}^{|V|}$ 表示词汇表 $V$ 上的概率向量。遵循,我们保持:
$$\hat{\ervw}_{k} = \ervw_{k}, \quad \forall k \in \{v \in [|V|]: \hat{\ervw}_{v} < 0.1 \cdot \max_{j \in [|V|]} \hat{\ervw}_{j}\}$$以防止分布尾部的扭曲。
当发生拒绝时,我们从调整后的残差分布中采样:
$$x_i \sim \texttt{norm}({\max(p(x_i)-\hat{p}(x_i), p(x_i)-q(x_i))})$$该采样策略保持了理论保证,我们证明生成的token遵循与直接从原始目标模型 $p(x_i)$ 采样相同的分布。
3. 实验设置
3.1 实现细节
目标LLM和草稿LLM:RAPID使用LLaMA-3.1(8B、70B)和Qwen2.5(7B、72B)作为目标LLM进行评估。我们实现了两种推测设置:(1)自推测,其中RAG草稿模型与目标LLM规模相同;(2)向上推测,其中较大的RAG草稿模型辅助较小的目标LLM。对于较小的模型(LLaMA-3.1-8B、Qwen2.5-7B),我们评估两种设置,而较大的模型(LLaMA-3.1-70B、Qwen2.5-72B)仅使用自推测。RAG草稿模型为每个步骤生成$\gamma=10$个token供目标LLM验证。
RAG设置:长上下文被分割成512-token的块,并使用BGE-M3模型编码为嵌入。我们根据与查询嵌入的余弦相似度检索top-$k$个块,过滤掉相似度低于0.3的检索块。检索上下文长度限制在4096 token和输入长度的1/24之间。
3.2 评估协议
基线:我们将RAPID与以下基线进行比较:(1)长上下文目标LLM(LC),其中目标LLM直接在长上下文上生成响应;(2)RAG,其中目标LLM在RAPID中草稿模型输入的检索上下文上生成响应;(3)朴素推测解码(SD),其使用与RAPID相同的目标和草稿LLM,但使用朴素长上下文目标分布;(4)MagicDec,其利用StreamingLLM来压缩草稿模型的KV缓存。
基准测试:我们在两个基准测试上评估RAPID和基线:(1)$\infty$Bench。我们在此基准上评估三种现实任务:长书问答(En.QA,指标:F1)、多项选择问答(En.MC,指标:准确率)和摘要(En.Sum,指标:ROUGE-L-Sum)。(2)LongBench v2,涉及上下文长度从8K到2M词的各种多项选择任务。
评估设置:我们使用LongBench v2(Long, CoT)子集进行效率评估,其中每个示例包含120K(token)上下文长度和最多1K生成token。效率指标包括:(1)预填充时间和(2)加速比,计算为每个目标LLM的方法吞吐量与LC吞吐量的比率。
4. 结果与分析
4.1 主要结果
我们在不同模型规模和基准测试上评估RAPID与基线。结果表明RAPID在提升长上下文推理的生成质量和效率方面都是有效的。
RAPID通过自推测整合了目标LLM和RAG草稿模型的优势。在自推测设置中,RAPID使用相同规模的模型作为目标和草稿,在模型家族中观察到一致的改进。对于LLaMA-3.1-8B,RAPID自推测在$\infty$Bench上达到42.83(vs LC的39.33,RAG的40.40)和LongBench v2上达到34.2%(vs LC的30.4%,RAG的33.4%)。类似改进也出现在LLaMA-3.1-70B($\infty$Bench上50.62 vs 45.07 LC,47.56 RAG)和Qwen2.5系列中。值得注意的是,RAPID有效地整合了LC和RAG方法的互补优势——虽然RAG在某些任务上表现出色(例如En.MC:79.04% vs LC的53.28%),LC在 others(例如En.QA:34.58% vs RAG的31.91%)。RAPID在推理过程中成功捕获这些互补优势,始终实现与其两个组成部分中较强的相当或更好的性能。
更大的RAG草稿模型通过有效的知识转移进一步提升性能。除了自推测,RAPID还支持一种独特的向上推测机制,其中较大的模型作为RAG草稿模型同时保持效率。这种设置产生更显著的改进:使用70B RAG草稿模型的LLaMA-3.1-8B在$\infty$Bench上达到49.98,在LongBench v2上达到40.2%的总体准确率,不仅超越了其自推测结果,甚至超越了LLaMA-3.1-70B的LC性能(36.2%)。
RAPID为长上下文推理展示超过2倍的加速。在自推测设置中,RAPID相对于LC基线实现了显著的加速(LLaMA-3.1-8B为2.10倍,LLaMA-3.1-70B为2.69倍),显著超越朴素SD和MagicDec。当使用较大草稿模型进行向上推测时,RAPID仍保持相当的吞吐量。
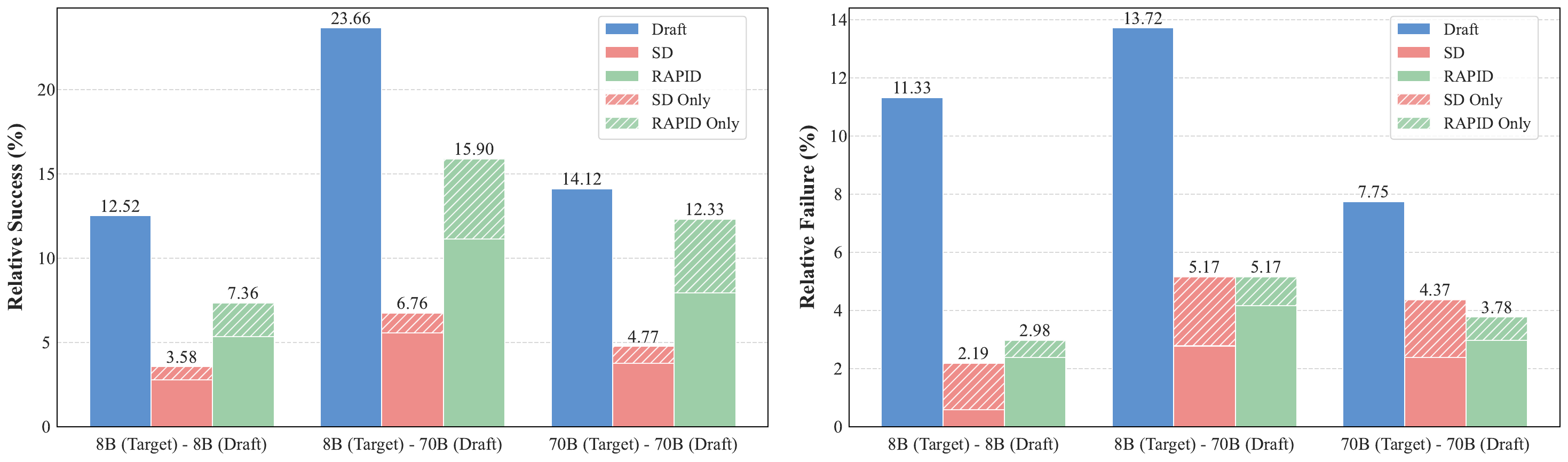
4.2 收益整合分析
RAPID在保持目标模型能力的同时纳入了RAG草稿模型的优势。为分析RAPID如何整合RAG草稿模型和目标LLM的优势,我们检查了RAG草稿模型、SD和RAPID在LongBench v2上的相对成功和失败。如图2所示,RAPID成功处理了目标LLM失败的额外案例,通过纳入RAG草稿模型的有益知识。同时,RAPID保持了目标LLM的能力,与单独使用RAG草稿模型相比表现出显著更低的失败率。这种RAG草稿模型收益与目标LLM能力低降的组合使RAPID能够超越目标和草稿模型。
RAPID展现出超越单独目标/草稿LLM的能力。最值得注意的是,我们观察到一种"涌现现象",其中RAPID成功处理了目标LLM和RAG草稿模型都单独失败的案例。这种涌现准确率随着RAG草稿模型变强而变得更加显著,从LLaMA-3.1-8B到LLaMA-3.1-70B。
4.3 上下文和检索长度的影响
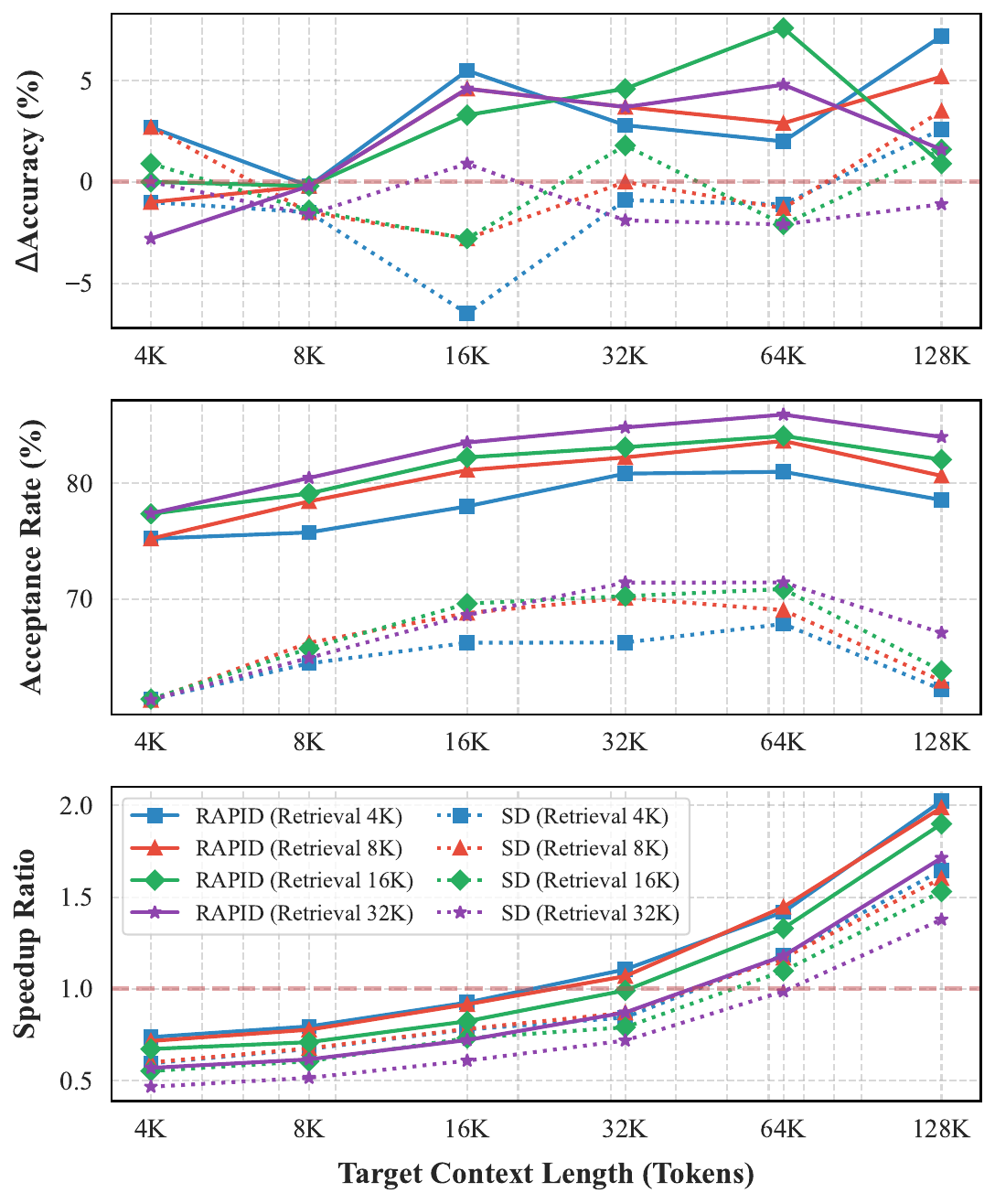
RAPID在各种上下文配置中展示有效性。我们分析了RAPID在不同目标上下文长度和RAG草稿模型检索长度下的表现。结果表明RAPID相对于朴素SD在所有配置中都具有一致的优势。首先,RAPID实现了显著更好的性能提升(2-8% Δ准确率)相对于长上下文基线,相比朴素SD的边际或负收益(-5-2%)。这种优越性能伴随着持续更高的接受率(75-85%对比60-70%)和更好的加速比。
RAPID为超过32K的长上下文推理实现加速。检索长度的影响揭示了一个有趣的效率-有效性权衡。在计算效率方面,当目标上下文长度超过32K时,RAPID实现加速(加速比>1.0倍),而SD需要超过64K的上下文才能展示加速。
4.4 生成质量分析
RAPID在实际应用中实现优越的生成质量和吞吐量。为评估RAPID在实际长上下文应用中的有效性,我们评估了其多轮对话生成的表现。我们构建了一个具有挑战性的评估数据集:对于前100个样本,我们保留它们的最后一轮查询,同时将它们之前的对话上下文分布在由另外500个样本组成的更长聊天历史中。结果显示,RAPID实现了4.21的生成质量分数,显著超越目标LLM(2.82)、RAG草稿模型(3.95)和朴素SD(2.94)。这种质量改进伴随着76.94%的鲁棒接受率(vs SD的56.34%)和18.18 token/秒的增强吞吐量(相比目标LLM加速1.7倍)。
4.5 对检索质量的鲁棒性
RAPID展示对检索质量的鲁棒性,并通过更强的草稿模型进一步增强。为评估RAPID关于检索质量的鲁棒性,我们进行压力测试,故意使用不相关的检索上下文,同时变化知识转移参数$\eta$。如表4所示,对于自推测(RAG草稿模型8B),即使在不相关检索上下文中,RAPID也保持性能收益(Δ准确率>0)和改进的效率(1.62倍-1.78倍加速)。然而,当$\eta>20$时,RAG草稿模型可能过度影响目标分布,导致性能下降。此外,使用70B作为草稿模型的向上推测展示更好的鲁棒性,在完全不相关的检索上下文中保持正性能收益。
5. 相关工作
5.1 推测解码
推测解码通过利用较小的草稿模型提出多个token进行单次验证来加速LLM推理。REST通过从构建的语料库检索可能的延续而不是使用草稿LLM生成来扩展起草机制。Ouroboros提出根据草稿短语从草稿LLM每步产生更长和更可接受的候选。灵感来自推测机制,Speculative RAG提出并行起草-验证机制来改进RAG质量。最近的工作如TriForce和MagicDec尝试通过KV缓存压缩技术将SD扩展到长上下文场景。然而,这种压缩方法通常导致弱化的草稿模型,在复杂应用中速度提升有限。相比之下,RAPID采用RAG草稿模型,在各种应用中保持高质量推测和显著加速。
5.2 长上下文推理加速
加速长上下文推理的研究主要关注两个方向:通过选择性保留或量化优化KV缓存操作,以及探索提示压缩方法。虽然这些方法提高了效率,但它们经常在没有任何质量保证的情况下 compromising 上下文信息。RAPID通过利用SD从长上下文LLM明确验证来保持生成质量,解决了这一限制,在效率和性能之间提供更可靠的平衡。
5.3 RAG与长上下文LLM
最近的研究揭示了RAG和长上下文LLM之间的互补优势。尽管长上下文LLM在基于文档的任务中表现优异,RAG在对话式问答等场景中展现优势。先前结合这些方法的尝试(如自反射路由和逐步RAG增强)严重依赖特定任务的提示工程。RAPID通过将RAG优势直接整合到解码过程中提供更原则化的解决方案,在保持两种范式优势的同时实现动态适应。
6. 结论
在本文中,我们引入RAPID,这是一种新颖的解码方法,弥补了推测解码在长上下文推理中的效率差距,同时通过检索增强推测提升了生成质量。RAPID的关键在于利用RAG草稿模型实现长上下文目标LLM的高效推测,以及一种检索增强目标分布,有效整合来自潜在更强草稿模型的知识。通过广泛实验,我们证明RAPID在不同模型规模和任务中成功实现了计算效率和生成质量的提升。具体而言,RAPID在自推测设置中实现了超过2倍的加速,同时保持性能优势,并通过使用更强的RAG草稿模型通过向上推测实现显著的质量提升。这些结果确立RAPID作为加速长上下文推理同时提升生成质量的实用解决方案。
论文简评
创新点
RAG草稿模型范式:首次提出使用RAG作为推测解码的草稿模型,开创了"检索增强推测"的新方向。
自推测与向上推测:提出两种新范式——同规模模型自推测,以及使用更大模型作为草稿的向上推测,为SD在长上下文场景的应用提供了新思路。
检索增强目标分布:通过推理时知识蒸馏机制,实现从RAG草稿模型到目标LLM的知识转移,有效整合两者优势。
超过2倍加速:在保持甚至提升生成质量的同时,实现长上下文推理超过2倍的加速。
局限性
检索质量依赖:性能受限于检索器的质量,不相关的检索上下文可能导致性能下降。
参数调优:知识转移强度$\eta$需要针对不同场景进行调优。
GPU资源需求:向上推测需要额外的GPU来服务RAG草稿模型。
应用场景
- 长文档问答:处理超过100K token的长文档分析
- 多轮对话系统:需要理解长聊天历史的对话系统
- 代码理解与分析:大型代码库的上下文理解
- 长篇内容生成:需要长上下文支持的创作任务
报告生成日期:2026年3月4日