论文报告:Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free
论文基本信息
| 项目 | 内容 |
|---|---|
| 论文ID | 2505.06708 |
| 标题 | Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free |
| 作者 | Zihan Qiu, Zekun Wang, Bo Zheng, Zeyu Huang, Kaiyue Wen, Songlin Yang, Rui Men, Le Yu, Fei Huang, Suozhi Huang, Dayiheng Liu, Jingren Zhou, Junyang Lin |
| 单位 | 阿里Qwen团队, 爱丁堡大学, 斯坦福大学, MIT, 清华大学 |
| 会议 | ACL 2025 |
论文摘要
门控机制已被广泛应用于从早期模型(如LSTM和Highway Networks)到最近的状态空间模型、线性注意力以及softmax注意力的各种架构中。然而,现有文献很少深入研究门控的具体作用。本工作通过全面的实验系统地研究了门控增强的softmax注意力变体。具体而言,我们对15B MoE模型(超过30种变体)和1.7B密集模型进行了全面比较,这些模型在3.5万亿token的数据集上训练。我们的核心发现是:在缩放点积注意力(SDPA)之后应用头特定的sigmoid门控——这一简单修改—— consistently improves performance(持续提升性能)。这种修改还增强了训练稳定性,容忍更大的学习率,并改善了扩展性质。通过比较各种门控位置和计算变体,我们将这种有效性归因于两个关键因素:(1)在softmax注意力的低秩映射中引入非线性;(2)应用依赖查询的稀疏门控分数来调制SDPA输出。值得注意的是,我们发现这种稀疏门控机制可以缓解"attention sink"并增强长上下文外推性能。我们还发布了相关代码和模型以促进未来研究。
论文主体分析
1. 引言
门控机制在神经网络中有着悠久的应用历史。早期的架构,如LSTM、Highway Networks和GRU,开创了使用门控来控制信息流并改善梯度传播的先河。这一原则在现代架构中仍然存在。最近的序列建模工作,包括状态空间模型和注意力机制,通常都应用门控来调制token-mixer组件的输出。尽管门控机制被广泛采用且经验上取得成功,但其功能和对模型性能的影响仍未得到充分探索。
研究动机:现有的研究往往将门控与其他架构因素混在一起,难以评估门控的真正贡献。例如,Switch Heads引入了sigmoid门控来选择top-K注意力头专家,但实验表明,即使简化为单一专家,门控本身也能带来显著的性能提升。这强烈表明门控本身具有重要的内在价值。类似地,在Native Sparse Attention (NSA)中,虽然展示了整体性能提升,但没有将门控机制的贡献与稀疏注意力设计本身的影响区分开来。
研究贡献:
- 系统地研究了门控机制在标准softmax注意力中的各种变体
- 发现SDPA输出后的头特定门控($G_1$)效果最好,可降低0.2 PPL并在MMLU上提升2分
- 识别出门控有效的两个关键因素:非线性和稀疏性
- 发现稀疏门控可以消除attention sink现象,增强长上下文外推性能
2. 门控注意力层
2.1 预备知识:多头Softmax注意力
给定输入 $X \in \mathbb{R}^{n \times d_{\text{model}}}$,其中 $n$ 是序列长度,$d_{\text{model}}$ 是模型维度,transformer注意力层的计算可分为四个阶段:
QKV线性投影:输入$X$通过学习到的权重矩阵$W_Q, W_K, W_V \in \mathbb{R}^{d_{\text{model}} \times d_k}$线性变换为查询$Q$、键$K$和值$V$: $$Q = XW_Q, \quad K = XW_K, \quad V = XW_V$$
缩放点积注意力(SDPA):计算查询和键之间的注意力分数,然后进行softmax归一化: $$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$$
多头拼接:在多头注意力中,上述过程并行重复$h$次,每个头有自己的投影矩阵: $$\text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \dots, \text{head}_h)$$
最终输出层:拼接的SDPA输出通过输出层$W_o$: $$O = \text{MultiHead}(Q, K, V)W_o$$
2.2 用门控机制增强注意力层
门控机制的形式化定义为: $$Y' = g(Y, X, W_\theta, \sigma) = Y \odot \sigma(XW_\theta)$$
其中$Y$是要调制的输入,$X$是用于计算门控分数的另一输入,$W_\theta$是门控的可学习参数,$\sigma$是激活函数(如sigmoid),$Y'$是门控输出。门控分数$\sigma(XW_\theta)$有效地充当动态过滤器,通过有选择地保留或擦除特征来控制信息流。
门控变体的五个关键维度:
位置:在QKV投影后($G_2, G_3, G_4$)、SDPA输出后($G_1$)、最终输出层后($G_5$)
粒度:
- Headwise:单个标量门控分数调制整个注意力头的输出
- Elementwise:门控分数是与$Y$维度相同的向量,实现细粒度调制
头特定或共享:
- Head-Specific:每个注意力头有自己特定的门控分数
- Head-Shared:$W_\theta$和门控分数在头之间共享
乘法或加法:
- Multiplicative Gating:$Y' = Y \cdot \sigma(X\theta)$
- Additive Gating:$Y' = Y + \sigma(X\theta)$
激活函数:SiLU和sigmoid
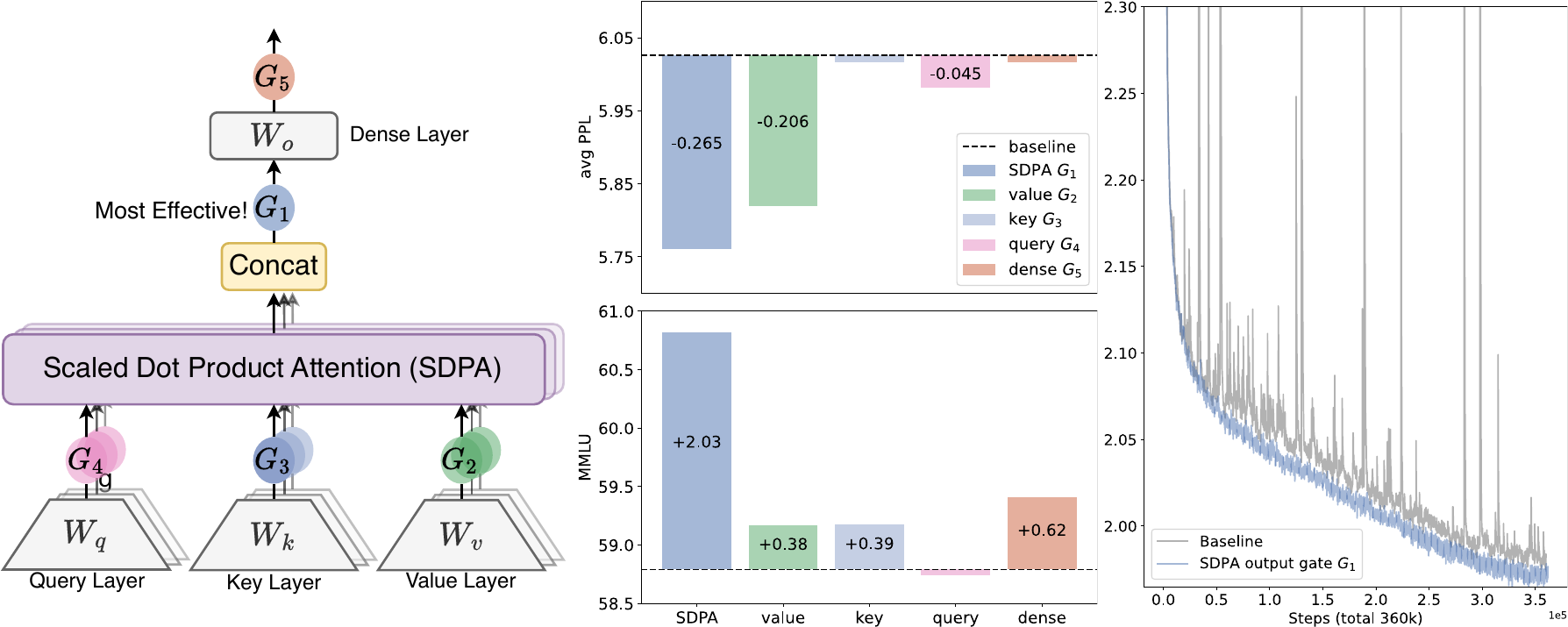
3. 实验
3.1 实验设置
模型架构:
- MoE模型:15B总参数,2.54B激活参数(15A2B),128个专家,top-8 softmax门控
- 密集模型:1.7B总参数
训练设置:
- 使用GQA(Group Query Attention)
- 在3.5T高质量token上训练,包含多语言、数学和通用知识内容
- 上下文序列长度为4096
- 门控引入的参数量很小,wall-time延迟小于2%
评估基准:
- Hellaswag(英文)
- MMLU(通用知识)
- GSM8k(数学推理)
- HumanEval(编程)
- C-eval和CMMLU(中文能力)
- Perplexity(PPL)
3.2 主要结果
MoE模型的门控注意力:
| 方法 | 激活函数 | 分数形状 | 参数量(M) | 平均PPL | Hellaswag | MMLU | GSM8k |
|---|---|---|---|---|---|---|---|
| Baseline | - | - | 0 | 6.026 | 73.07 | 58.79 | 52.92 |
| SDPA Elementwise $G_1$ | sigmoid | $n\times q \times d_k$201 | 5.761 | 74.64 | 60.82 | 55.27 | |
| v Elementwise $G_2$ | sigmoid | $n\times k \times d_k$25 | 5.820 | 74.38 | 59.17 | 53.97 | |
| SDPA Headwise $G_1$ | sigmoid | $n\times q$1.6 | 5.792 | 74.50 | 60.05 | 54.44 | |
| v Headwise $G_2$ | sigmoid | $n\times q$0.2 | 5.808 | 74.38 | 59.32 | 53.53 |
关键发现:
- SDPA和Value输出门控都有效,$G_1$位置效果最好
- 头特定门控很重要,虽然引入参数少(少于2M),但提升显著
- 乘法门控优于加法门控
- Sigmoid激活函数优于SiLU
- 在$G_1$和$G_2$位置添加门控可将PPL降低超过0.2
密集模型的门控注意力:
| 方法 | 最大LR | 平均PPL | HumanEval | MMLU | GSM8k |
|---|---|---|---|---|---|
| Baseline | 4.0e-3 | 7.499 | 28.66 | 50.21 | 27.82 |
| SDPA Elementwise | 4.0e-3 | 7.404 | 29.27 | 51.15 | 28.28 |
| Baseline | 4.5e-3 | 6.180 | 34.15 | 59.10 | 69.07 |
| SDPA Elementwise | 4.5e-3 | 6.130 | 37.80 | 59.61 | 70.20 |
关键发现:
- 门控在各种设置下都有效
- 门控提高了稳定性,减少了loss spikes
- 门控允许使用更大的学习率(从4.0e-3到8.0e-3)
- 门控使模型能够使用更大的batch size
4. 分析:非线性和稀疏性,以及无Attention-Sink
4.1 非线性增强低秩映射的表达能力
在多头注意力中,第$i$个token在第$k$个头的输出可以表示为: $$o^k_i = \left(\sum_{j=0}^{i} S^k_{ij} \cdot X_j W_V^k \right) W^k_O = \sum_{j=0}^{i} S^k_{ij} \cdot X_j (W_V^k W^k_O)$$
我们可以将$W_V^k W^k_O$合并为一个低秩线性映射。由于$d_k < d_{\text{model}}$,这限制了表达能力。
添加门控($G_2$位置)对应于: $$o^k_i = \left(\sum_{j=0}^{i} S^k_{ij} \cdot \text{Non-Linearity-Map}(X_j W_V^k) \right) W^k_O$$
添加门控($G_1$位置)对应于: $$o^k_i = \text{Non-Linearity-Map}\left(\sum_{j=0}^{i} S^k_{ij} \cdot X_j W_V^k \right) W^k_O$$
结论:门控在$W_V$和$W_O$之间引入了非线性,增强了低秩线性变换的表达能力。
4.2 门控引入输入依赖的稀疏性
关键发现:
有效的门控分数是稀疏的:SDPA输出门控(Element/head-wise)表现出最低的平均门控分数,分布高度集中在0附近
头特定的稀疏性很重要:跨注意力头强制共享门控分数会增加整体门控分数并削弱性能提升
依赖查询很重要:SDPA输出门控分数来自当前查询对应的隐藏状态,而值门控分数来自与过去的键和值相关的隐藏状态
减少稀疏性会使效果变差:使用NS-sigmoid(将门控分数限制在[0.5, 1.0])会削弱性能
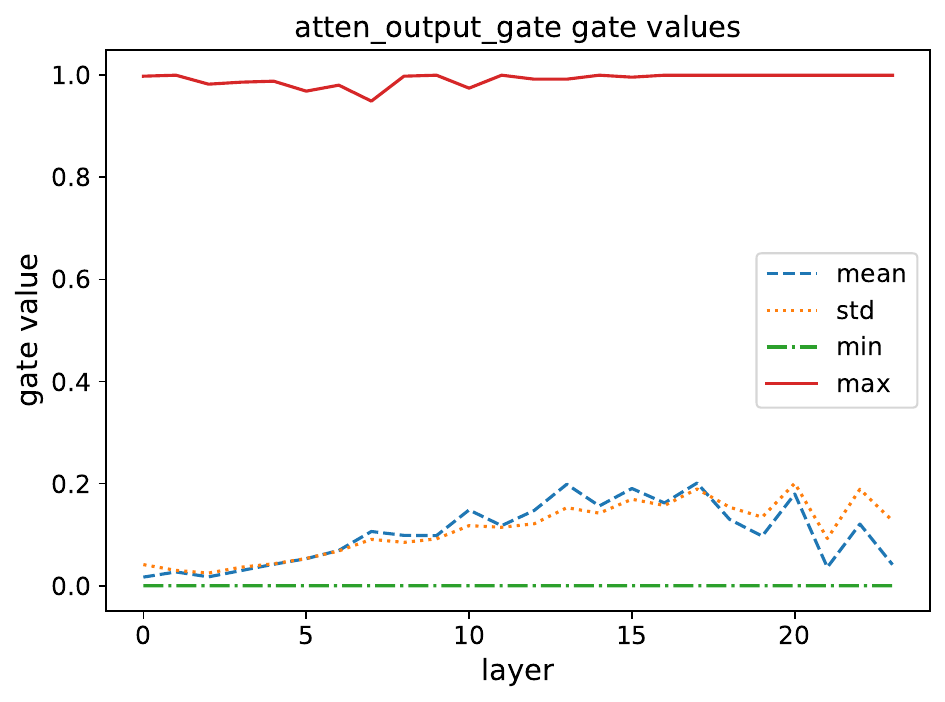
4.3 SDPA输出门控减少Attention-Sink
Attention-Sink现象:初始token不成比例地主导注意力分数
- Baseline模型:平均46.7%的注意力分数指向第一个token
- 门控模型:降低到4.8%
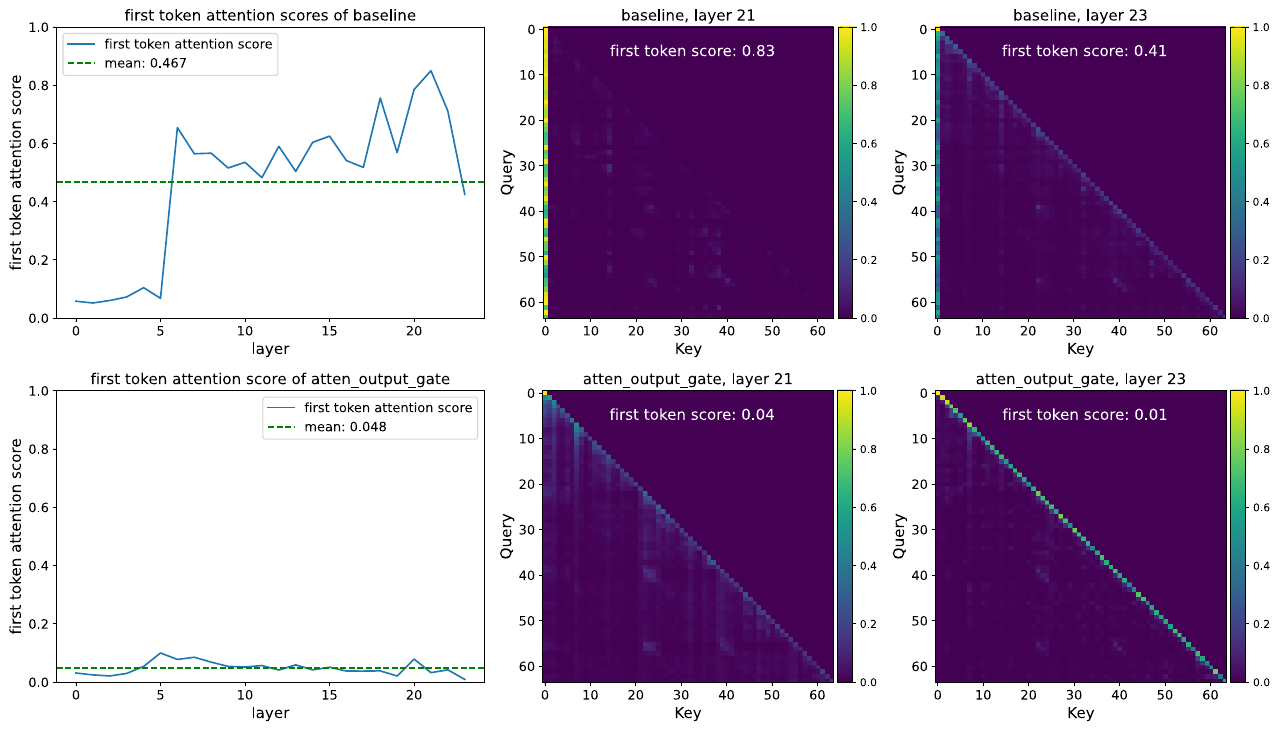
关键发现:
- 头特定和元素级别的sigmoid门控大幅减少了分配给第一个token的注意力分数
- 强制跨头共享门控或仅在值投影后应用门控会减少大规模激活,但不减少第一个token的注意力
- 减少门控的输入依赖性或使用NS-sigmoid减少稀疏性会加剧大规模激活和attention sink
结论:输入依赖的、头特定的SDPA输出门控引入了显著的稀疏性,从而缓解了attention sink问题。
4.4 SDPA输出门控促进上下文长度扩展
| 方法 | 4k | 8k | 16k | 32k | 64k | 128k | |------|-----|-----|------|------|------|------| | Baseline | 88.89 | 85.88 | 83.15 | 79.50 | - | - | | SDPA-Gate | 90.56 | 87.11 | 84.61 | 79.77 | - | - | | YaRN Extended |||||| | Baseline | 82.90 | 71.52 | 61.23 | 37.94 | 37.51 | 31.65 | | SDPA-Gate | 88.13 | 80.01 | 76.74 | 72.88 | 66.60 | 58.82 |
关键发现:
- 在32k设置下,门控模型略优于baseline
- 当使用YaRN将上下文扩展到128k时,baseline下降显著(-41.56在32k),而门控模型下降较小(-6.89)
- 在64k和128k长度下,门控注意力模型显著优于baseline
解释:Baseline模型依赖attention sink来调整注意力分数的分布。当使用YaRN等技术修改RoPE base时,attention sink模式难以适应,导致性能明显下降。相比之下,带门控的模型主要依赖输入依赖的门控分数来控制信息流,对此类变化更加稳健。
论文简评
创新点
系统性地研究门控机制:首次对softmax注意力中的门控变体进行了全面系统的实验分析,覆盖30多种变体
发现关键有效位置:确定了SDPA输出后($G_1$位置)是应用门控的最佳位置
揭示两个核心机制:
- 非线性:增强$W_V$和$W_O$之间的表达能力
- 稀疏性:引入输入依赖的稀疏门控
消除Attention-Sink:首次展示了稀疏门控可以有效消除attention sink现象
提升训练稳定性:门控显著减少训练中的loss spikes,允许更大的学习率
局限性
理论解释不足:虽然实验表明门控有效,但对非线性在注意力动态中的更广泛影响缺乏深入的理论解释
长上下文外推:虽然观察到消除attention sink改善了长上下文扩展性能,但没有提供严格理论解释attention sink如何影响模型外推到更长序列的能力
实验规模:虽然实验规模较大(15B MoE + 1.7B Dense,3.5T tokens),但主要通过消融实验验证
应用场景
- 大语言模型训练:任何使用Transformer架构的LLM都可以从门控注意力中获益
- 长上下文模型:需要长上下文能力的应用(如文档摘要、代码理解)
- 训练稳定性:训练不稳定或需要使用大学习率的场景
- 模型压缩:稀疏门控可以用于模型剪枝或压缩
可改进方向
- 理论分析:更深入地分析门控引入的非线性对注意力机制的影响
- 与其他架构结合:将门控注意力与其他技术(如RoPE、位置编码)更好地结合
- 更高效的实现:减少门控带来的计算开销
- 更大规模验证:在更大规模模型上验证门控的效果
参考图片
- 图1:门控位置和性能对比
- 图2:注意力分布对比(attention sink分析)
- 图3:门控分数分布
- 图4:门控前后hidden states统计
- 图5:稀疏性分析
- 图6:逐层大规模激活和attention sink分析