TokenDance:通过集体 KV Cache 共享扩展多智能体 LLM 服务
一、论文摘要
多智能体 LLM 应用采用同步轮次执行模式,其中中央调度器收集所有智能体的输出并重新分发组合后的上下文。这种All-Gather通信模式产生了大量 KV Cache 冗余,因为每个智能体的提示包含相同的共享输出块,但现有的复用方法无法有效利用这一特征。
本文提出了 TokenDance,一个通过利用 All-Gather 模式进行集体 KV Cache 共享来扩展并发智能体数量的系统。TokenDance 的 KV Collector 在一个集体步骤中对完整轮次执行 KV Cache 复用,因此复用共享块的成本只支付一次,与智能体数量无关。其 Diff-Aware Storage 将兄弟缓存编码为针对单个主副本的块稀疏差分,在代表性工作负载上实现了 $11$--$17\times$ 的压缩率。在 GenerativeAgents 和 AgentSociety 上的评估表明,TokenDance 在 SLO 要求下支持比 vLLM(带前缀缓存)多 $2.7\times$ 的并发智能体,将每个智能体的 KV Cache 存储减少最多 $17.5\times$,并在每个请求的位置无关缓存上实现了最多 $1.9\times$ 的预填充加速。
二、基本信息
论文 ID: 2604.03143 标题: TokenDance: Scaling Multi-Agent LLM Serving via Collective KV Cache Sharing 作者: Zhuohang Bian, Feiyang Wu, Chengrui Zhang, Hangcheng Dong, Yun Liang, Youwei Zhuo 单位: 北京大学、上海交通大学 会议/期刊: ACM 原文保存位置: ~/.openclaw/workspace/papers/20260415_TokenDance/source/ 报告生成日期: 2026-04-15
三、论文主体分析
1. 引言
大语言模型(LLM)是多智能体编程、搜索和仿真平台的执行引擎。社会仿真将多智能体服务推向极限:它需要许多智能体同时运行,复杂的多轮交互中每个智能体的上下文随时间增长,以及进一步扩展提示长度的工具使用。随着这些应用从几个智能体增长到生产环境中的数十甚至数百个,GPU 内存成为主要的扩展约束。每个智能体维护一个跨交互轮次持久存在的 KV Cache,所有活跃智能体的缓存必须同时共存于 GPU 内存中。因此,多智能体 LLM 服务的主要挑战是在固定内存预算下最大化可并发运行的智能体数量。
这种内存压力有其结构性根源。多智能体框架如 OpenClaw 和 MoltBook 采用同步轮次组织执行:每个智能体产生输出,中央调度器收集所有输出,并重新分发组合上下文给每个智能体进入下一轮。我们将这种循环数据流称为 All-Gather (AG) 模式,源于分布式计算中的相应集合操作。该模式直接解释了内存问题。如图 1 所示,每个智能体在轮次 $t{+}1$ 的提示组合了私有历史 ($H$) 与完整的共享输出块集合 ($O$)。由于私有历史长度不同,相同的共享块在不同提示中位于不同的绝对位置,导致服务引擎无法识别重叠。结果是 GPU 内存中有 $N$ 个几乎相同的 KV Cache。因此,内存随智能体数量增长而非随唯一上下文量增长。
图 1:All-Gather 提示结构。所有智能体接收相同的输出块 ($O$),但由于每个提示有自己的私有历史 ($H$) 且可能使用不同的块顺序,这些块出现在不同位置。这种结构出现在遵循 All-Gather 模式的任何多智能体应用中。
:::
图 2 量化了这种冗余的规模。在 80 GB A100 GPU 上服务 Qwen2.5-14B,我们比较了 10 个多智能体会话(总共 250 个智能体子请求)与 250 个独立单请求。多智能体工作负载消耗 41.5 GiB 的 KV Cache 存储——占池的 99.3%——而独立请求仅使用 24.8 GiB (59.2%)。延迟影响立即显现:多智能体会话达到 P99 延迟 136 秒,因为内存池从一开始就饱和,而独立请求起始较低并逐渐上升至 125 秒。差异在于独立请求完成后释放其 KV Cache,而多智能体 KV Cache 必须跨轮次共存,导致池饱和并迫使调度器抢占和交换。
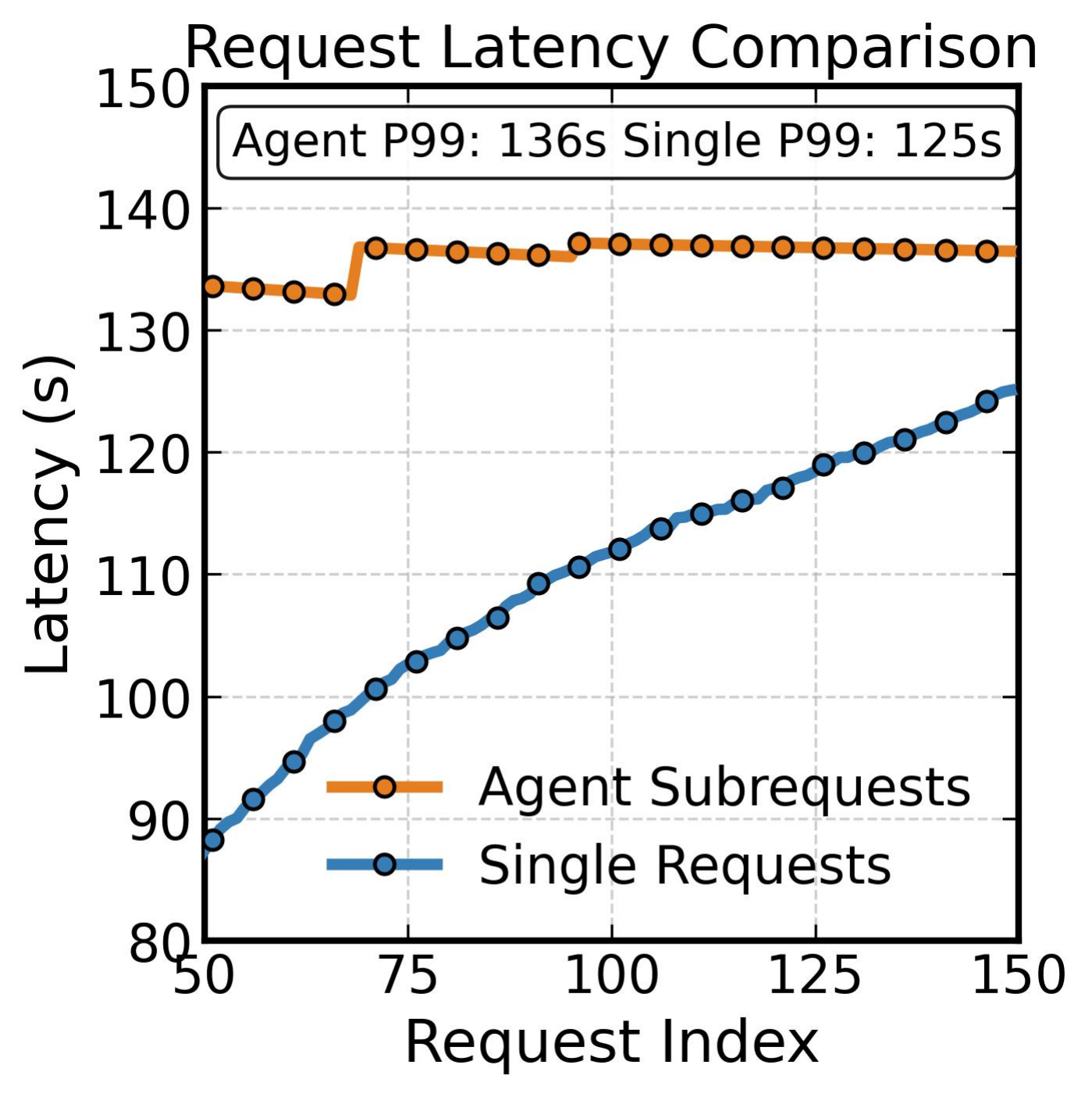
图 2(a):子请求延迟与请求索引的关系。
:::
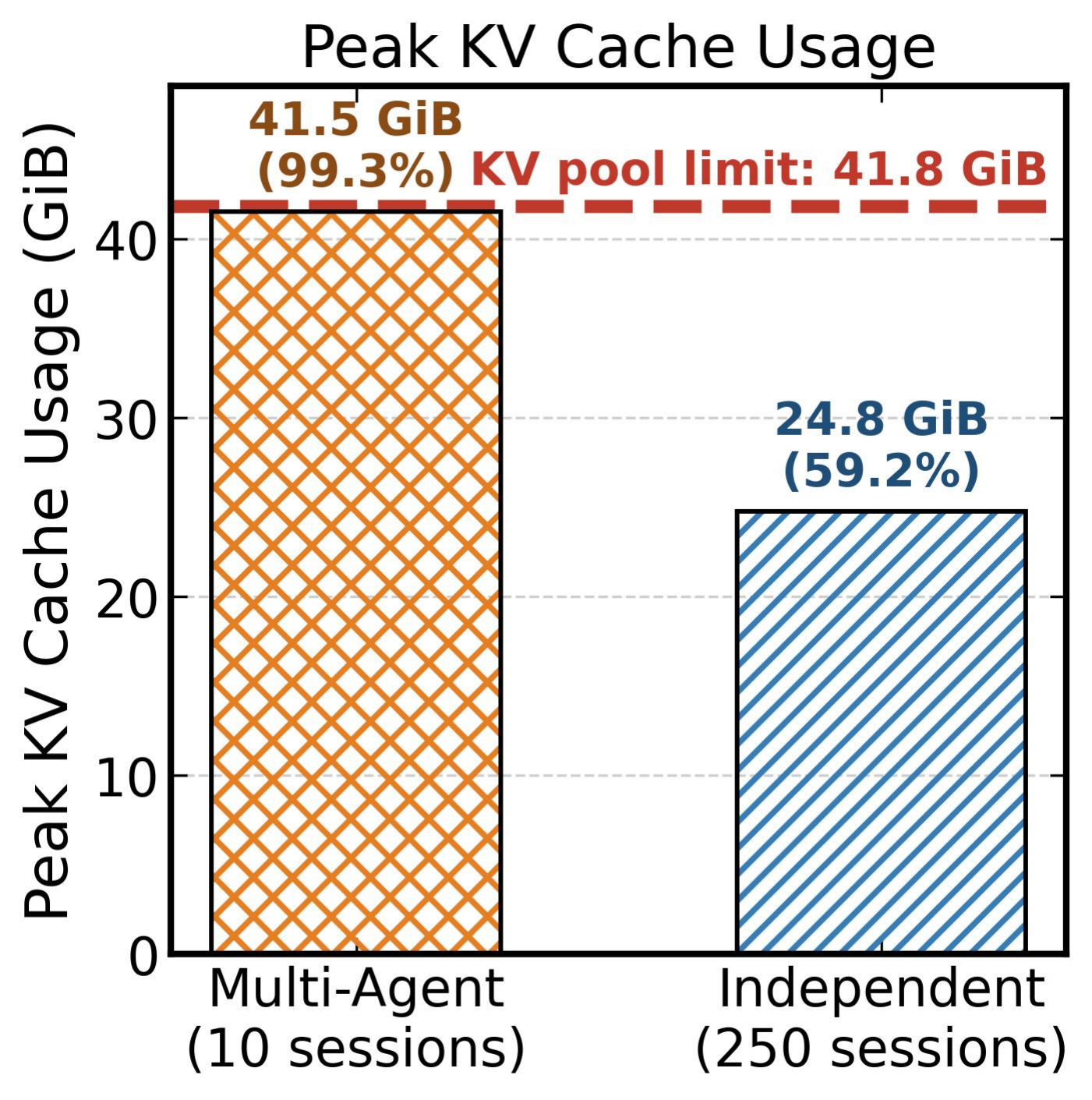
图 2(b):两种工作负载的峰值 KV Cache 使用量。
:::
现有服务系统无法利用这种冗余,因为它们在错误的粒度上操作。vLLM 和 SGLang 等系统将每个智能体子请求视为独立推理请求,对每个请求应用前缀缓存或位置无关缓存。Parrot、Autellix 和 Tokencake 等智能体感知调度器优化每个子请求何时运行并管理卸载,但不改变结果 KV Cache 如何计算或存储;每个智能体仍持有完整的独立缓存副本。缺失的能力是轮次级 KV Cache 优化:检测同一轮次中的智能体共享大部分上下文并利用这一重叠来减少计算和内存成本。然而,利用这一重叠需要解决两个特定问题。
第一个问题是复用效率低。每个智能体在新轮次的提示包含私有历史和上一轮的共享输出块集合。由于历史长度不同且调度器可能选择不同的块顺序,相同的共享块在不同请求中出现在不同的绝对位置。如图 1 所示,块 $O_1$ 在每个智能体的提示中起始偏移不同。前缀缓存只从位置零匹配 token,因此一旦私有历史分化就无法检测任何共享。位置无关缓存 (PIC) 方法消除了这一约束,可以在任意偏移复用块,但仍分别处理每个请求:在 $N$ 智能体轮次中,相同的共享块触发 $N$ 次独立的复用通过,为本质上轮次级共享机会支付每个请求的开销。
第二个问题是存储效率低。在智能体共享大部分轮次上下文的 All-Gather 工作负载中,复用后的 KV Cache 几乎相同。原因是结构性的:共享输出块从相同的缓存源复用,因此它们在所有智能体中产生相同的 KV Cache 值;唯一不同的条目是每个智能体从自己历史重新计算的 token,通常只占总序列的小部分。图 3 定量确认了这一点:在 8 智能体 GenerativeAgents 轮次中,逐块相似度范围为 91% 至 97%,意味着缓存数据的大部分在智能体间重复。因此每个智能体存储一个完整 KV Cache 浪费了大部分 GPU 内存预算,直接限制了多少智能体可以保持活跃。
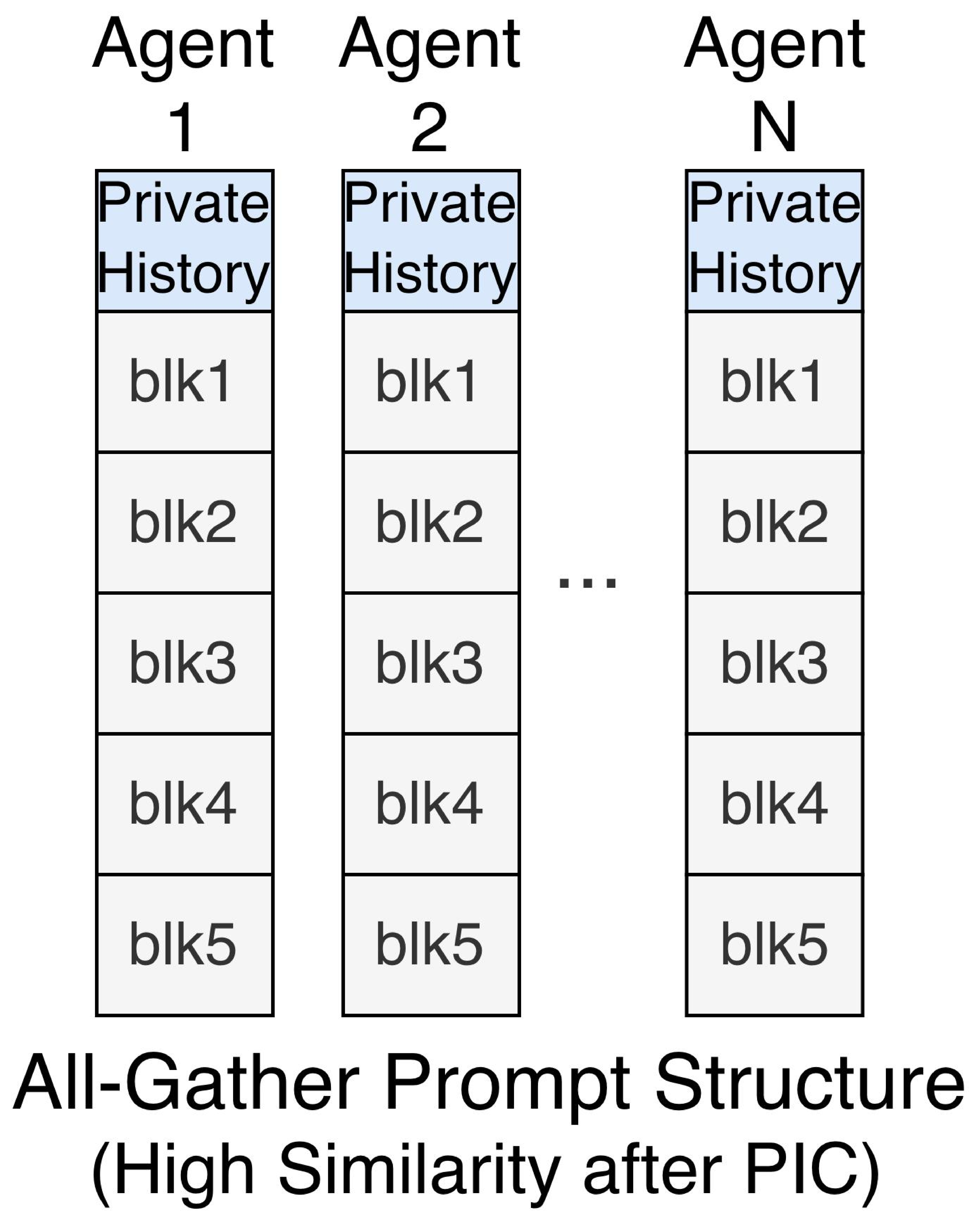
图 3(a):结构重叠示意图。
:::
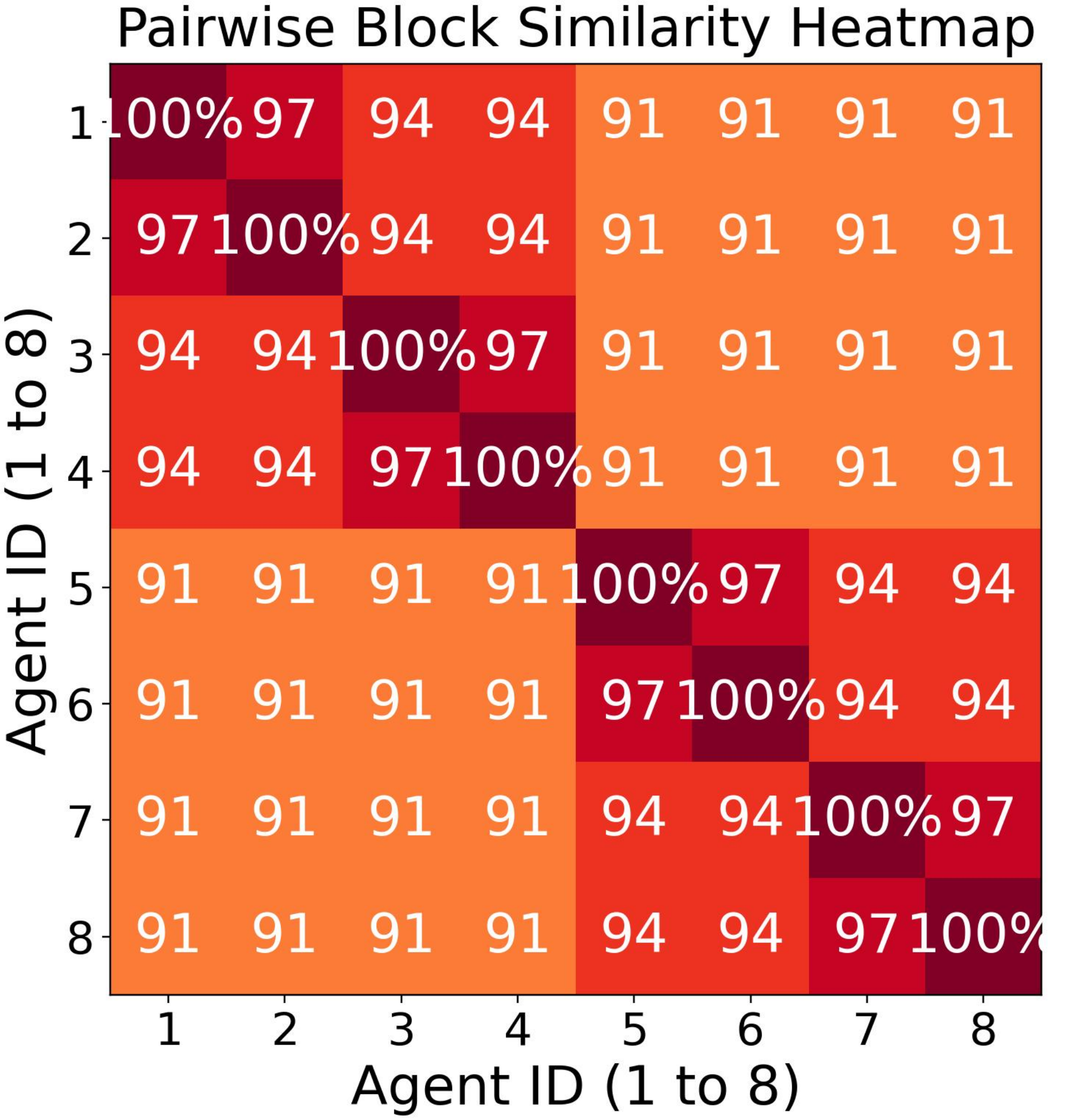
图 3(b):逐块相似度测量。
:::
本文提出 TokenDance,一个通过利用 All-Gather 模式进行集体 KV Cache 共享来扩展本地 GPU 上并发智能体数量的系统。TokenDance 不是优化单个请求,而是在多智能体轮次整体上操作。它将复用计算分摊到轮次中所有智能体,使得共享块的成本只支付一次与智能体数量无关,并将 KV Cache 存储压缩为仅保留智能体间差异,使内存成本随实际差异而非智能体数量增长。
我们在多智能体社会仿真框架 GenerativeAgents 和 AgentSociety 上评估 TokenDance。与带前缀缓存的 vLLM 相比,TokenDance 将端到端延迟减少最多 $2.3\times$,KV Cache 存储减少 94%。与 CacheBlend 相比,TokenDance 在预填充阶段实现 $1.9\times$ 加速。这些收益直接转化为更高的智能体容量:在相同延迟目标下,TokenDance 支持最多 $2.7\times$ 的并发智能体。
2. 背景
2.1 All-Gather 模式
如第 1 节所述,All-Gather 模式以同步轮次组织多智能体执行,其中调度器收集所有智能体输出并重新分发组合上下文。我们现在形式化这一结构。
对于有 $N$ 个智能体的系统,每个智能体 $i$ 维护私有历史 $H_i^t$,包含其系统提示和截至轮次 $t$ 的先前交互。在轮次 $t$,每个智能体 $j$ 产生输出块 $O_j^{t}$。共享的轮次输出集合为:
$$\mathcal{O}^{t} = \{O_1^{t}, O_2^{t}, \ldots, O_N^{t}\}$$智能体 $i$ 在轮次 $t+1$ 的提示为:
$$P_i^{t+1} = H_i^t \Vert \Pi_i(\mathcal{O}^{t})$$其中 $\Pi_i$ 是调度器为智能体 $i$ 定义的共享输出块布局。轮次中的每个提示包含相同的共享输出块和一个私有历史,且共享块在不同请求中出现在不同的绝对位置,因为私有历史长度不同。
2.2 LLM 服务中的 KV Cache 复用
LLM 服务是内存受限的:系统存储 KV Cache 以避免为先前 token 重新计算注意力键和值,管理这些缓存是扩展系统容量的主要挑战。现有复用方法分为两类。
前缀缓存,由 vLLM 和 SGLang 使用,仅当新请求与存储序列共享精确 token 前缀时复用缓存张量。这对共享公共系统提示的请求效果好,但一旦每个智能体的私有历史导致前缀分化就失效。
位置无关缓存 (PIC) 方法通过在任意偏移恢复共享块消除了这一约束。核心思想是纠正位置编码差异:PIC 方法首先应用 RoPE 旋转将缓存键与新请求中的目标位置对齐,然后计算旋转缓存值与新计算值之间的键差异以识别重要位置——两个值显著不同的 token 位置。只有这些重要位置被选择性重新计算,其余位置直接复用旋转缓存值。这以额外旋转和重新计算成本恢复了前缀之外的共享,以及在复用但未重新计算位置有轻微精度权衡。

图 4:每个请求的 PIC 复用(上)与 TokenDance 的集体复用(下)。现有 PIC 方法独立处理每个智能体的共享块,重复 $N$ 次 RoPE 旋转和重要位置选择。TokenDance 将 $N$ 个请求分组并为轮次执行这些操作一次。
:::
2.3 现有服务系统的局限
All-Gather 模式创建了现有服务系统无法利用的特定冗余组合。我们将相关工作分为两类并解释各自的不足。
智能体感知、计算中心调度器。 Parrot、Autellix 和 Teola 将应用级依赖图注入服务后端以优先关键请求并减少队头阻塞。ScaleSim 估计未来调用距离以在仿真工作负载中指导预取。这些系统决定每个请求何时运行,但不控制结果 KV Cache 如何计算或存储。底层内存分配器仍将每个智能体的缓存视为独立对象。因此,非关键智能体的突发可以驱逐关键智能体的缓存,无论调度如何。这些系统都无法检测 All-Gather 轮次中的 $N$ 个请求共享相同的输出块,因此复用工作和存储占用都没有减少。
KV Cache 中心、智能体无关引擎。 vLLM 和 SGLang 通过前缀匹配复用缓存张量,一旦私有历史从位置零分化就失效。CacheBlend 和 EPIC 通过在任意偏移复用 KV Cache 块解除位置约束,但仍分别分析每个请求:$N$ 个智能体对相同共享块触发 $N$ 次独立复用通过。Mooncake 和 CacheGen 通过分解和压缩扩展缓存池,但其策略由全局内存压力驱动,而非轮次结构。Tokencake 在 KV Cache 中心后端之上添加智能体感知调度,主动卸载停滞的智能体并为关键智能体保留内存。在所有这些系统中,最终结果相同:每个智能体持有密集的独立 KV Cache 副本,即使同一轮次中超过 90% 的缓存块在智能体间相同也不释放存储。
图 4 对比了这种每个请求的方法(上)与 TokenDance 引入的集体替代方案(下)。
3. 概述
TokenDance 通过解决冗余复用计算和冗余 KV Cache 存储来扩展本地 GPU 在 All-Gather 系统中可支持的活跃智能体数量。关键设计原则是将优化单元从单个请求提升到 All-Gather 轮次:轮次中智能体间共同的每个操作执行一次并共享,只有每个智能体的差异单独处理。图 5 展示了实现这一原则的三个组件。
图 5:TokenDance 概述。轮次感知提示接口保留块边界使运行时能识别共享内容;集体 KV Cache 复用将复用成本分摊到轮次中所有智能体;带融合恢复的差分感知存储将每个智能体 KV Cache 压缩为仅保留智能体间差异。
:::
轮次感知提示接口(第 4.1 节)通过在相邻块之间插入分隔符 token 来保留每个提示的逻辑块结构,使运行时即使在不同绝对位置也能识别共享块。集体 KV Cache 复用算法(第 4.2 节)利用这一结构在一遍中对兼容请求组执行复用,每轮次而非每请求支付复用开销一次。差分感知存储方案(第 4.3 节)将兄弟缓存编码为针对共享主副本的稀疏差分,融合恢复路径(第 4.4 节)在 GPU 传输期间应用这些差分以避免单独重建步骤。这些组件共同减少每个额外智能体添加的计算工作和存储成本,允许相同硬件以相同服务水平维持更多智能体。
4. TokenDance 设计
TokenDance 的设计始于 All-Gather 应用结构与服务系统之间的不匹配。多智能体应用以轮次通信,但服务系统接收扁平 token 流,失去私有和共享块之间的逻辑边界,并将每个请求视为独立。
这种不匹配产生了三个复合效率问题。首先,运行时无法跨请求识别共享块,因为位置基索引将内容身份与绝对偏移混淆。其次,位置无关复用方法为轮次中的每个请求重复相同分析,即使所有请求消费相同的共享块。第三,即使复用后,结果 KV Cache 几乎相同,系统仍每个请求存储一个完整密集副本。累积结果是膨胀的每个智能体 KV Cache 成本,直接限制了并发智能体数量。
TokenDance 通过两个设计规则解决这些效率问题。首先,保持轮次结构可见直到运行时可以使用它。其次,为每个请求保留一个正确缓存状态,同时共享轮次中真正共同的计算工作和状态。第一个规则导致轮次感知接口(第 4.1 节)和集体 KV Cache 复用(第 4.2 节)。第二个规则导致差分感知存储和融合差分恢复(第 4.4 节)。本节其余部分详细描述每个组件。
4.1 轮次感知提示接口
运行时如果只接收扁平 token 流就无法利用 All-Gather 模式。TokenDance 提供轮次感知提示接口来保留每个提示的逻辑块结构,使运行时即使在不同绝对位置也能识别共享块。
遵循 All-Gather 模式的任何多智能体框架都可以通过最小代码变更采用此接口。如果应用不遵循该模式,TokenDance 回退到标准单请求路径,无性能损失。
应用为每个智能体组装一个提示,并在相邻逻辑块之间插入保留分隔符 token <TTSEP>。图 6 展示了轮次中三个智能体的示例。每个提示包含一个私有历史块和相同的共享输出块集合,中间有分隔符 token。分隔后的块使请求间的可复用关系明确:私有历史、每个共享智能体更新和轮次任务在分词后都可单独识别。
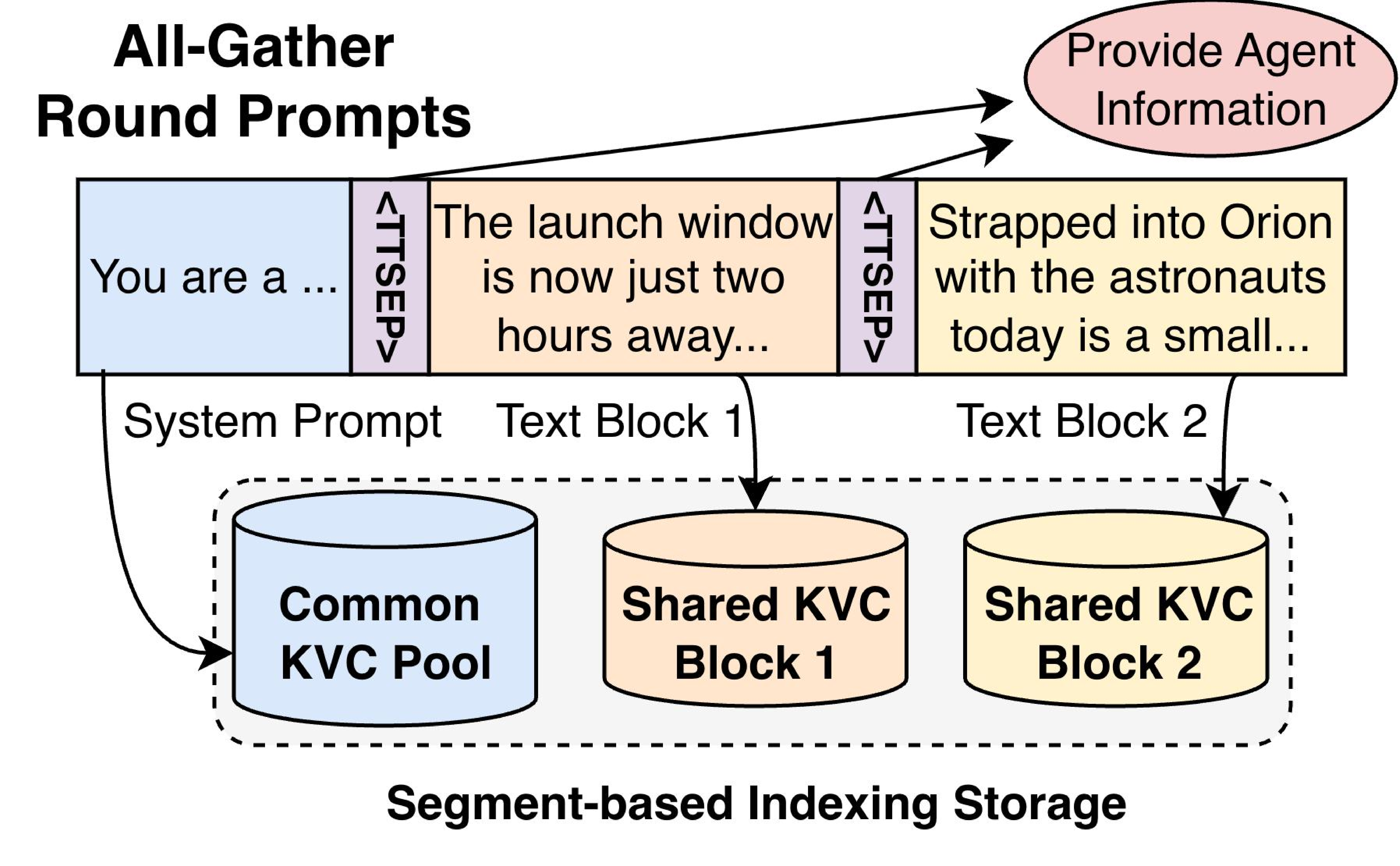
图 6:TokenDance 轮次感知提示接口示例。每个提示由私有历史块和共享输出块集合组成,中间有保留分隔符 token (<TTSEP>)。
:::
一旦块边界可见,运行时从固定大小块哈希切换到基于段的哈希。每个共享更新由其自己的内容段索引,而非在一个长提示中的绝对位置。因此,包含相同共享更新的两个请求将该更新映射到相同缓存对象,即使其私有历史长度不同。这是将 All-Gather 模式转化为服务优化的第一步:运行时现在知道哪些块是共享的,可以在块级而非前缀级推理复用。
4.2 集体 KV Cache 复用
一旦轮次结构可见,下一个问题是重复的复用工作。现有位置无关缓存 (PIC) 方法可以恢复前缀之外的共享,但仍独立处理每个请求。在 $N$ 智能体轮次中,运行时对相同共享块集合执行 $N$ 次独立复用通过。每次通过应用 RoPE、计算键差异和选择重要位置——所有操作跨请求产生几乎相同结果,因为共享块内容相同。这种每个请求冗余与 All-Gather 模式不匹配,其中共享轮次更新对轮次中每个请求都相同。
TokenDance 通过集体 KV Cache 复用解决这一冗余,如图 7 所示。KV Collector 不独立处理每个请求,而是将轮次中的 $N$ 个请求分组,执行一次共享 RoPE 旋转和一次共享重要位置选择通过,然后只更新每个请求缓存中不同的位置。
图 7:三个智能体 All-Gather 轮次的集体 KV Cache 复用。左:每个智能体的提示包含私有部分和不同顺序的相同共享块。右:vLLM 从头计算所有三个 (T1);每个请求 PIC 独立处理每个请求 (T2);TokenDance 将它们分组并跨组共享 RoPE 和重要位置选择工作 (T3),每轮次支付复用开销一次。
:::
分组兼容请求。 KV Collector 收集来自同一 All-Gather 轮次的提示跨度兼容于集体处理的请求。兼容性要求请求有相同的活跃提示长度、缓存层可见的相同缓存跨度,以及执行引擎中不重叠的槽映射。这些是确保锁步分层处理的执行约束;不满足这些约束的请求回退到单独组或单请求路径。
分层集体复用。 对于每个兼容组,运行时以锁步驱动分层检索和模型执行。每层,KV Collector 将组中所有请求的 Q 和 K 张量拼接为一个组合张量,并应用单一批次 RoPE 调用。在配置的检查层,运行时在一次批次差异通过中将旋转键与整个组的缓存键比较。此通过同时为每个请求识别重要位置——缓存值与新计算值显著不同的 token 位置。运行时然后只刷新每个请求缓存 K 和 V 张量中那些重要位置。后续层直接使用检查层识别的重要位置集,不重复差异计算。
因此,昂贵的操作——RoPE 旋转和键差异分析——为组执行一次而非每请求一次。只有最终缓存更新保持请求特定,因为每个请求的私有历史在需要刷新的位置产生不同值。在请求中心路径中,复用分析开销随智能体数量线性增长。在 TokenDance 中,组每层支付一次共享 RoPE 通过和一次共享差异分析通过,只有每个位置刷新随智能体数量扩展。随着轮次中智能体数量增长,这种分摊减少了每轮次的总复用工作。这种减少是扩展收益的计算侧。
集体分摊与底层每个位置恢复方法解耦。当前原型使用 CacheBlend 的选择性重新计算作为默认后端,但任何接受一组 token 位置并返回校正 K/V 张量的 PIC 方法可以通过适配器接口作为直接替代。
复用计划输出。 集体 KV Cache 复用还产生 Diff-Aware Storage 后续消费的元数据。复用路径记录组成员身份、累积每个请求偏差分数和被选为主的请求。主请求语义上无特殊之处,它只是恢复结果最接近组公共结构的请求,通常是具有从共享块最低总偏差的请求。选择好的主最小化 Diff-Aware Storage 必须为其余请求保留的稀疏校正大小。因此复用计划作为本小节计算优化与下一小节存储优化之间的桥梁。
4.3 差分感知存储
集体 KV Cache 复用消除了冗余计算,但不消除冗余存储。复用完成一轮次后,系统仍每个请求持有一个密集 KV Cache。这是浪费的,因为 All-Gather 轮次中的请求共享大部分逻辑块,只在私有历史和少量位置敏感更新上不同。如果系统完整存储每个恢复结果,只是将冗余从前缀计算转移到内存容量。
这个问题对多智能体服务尤为严重,因为轮次重复且智能体状态跨轮次保持活跃。在有 $N$ 智能体运行 $R$ 轮次的系统中,每智能体每轮次存储一个完整缓存导致内存消耗以 $O(N \times R)$ 增长。如果系统存储许多近似副本 KV Cache,内存压力快速上升,活跃智能体数量下降。因此存储必须利用复用所利用的相同 All-Gather 结构:轮次中的请求结构相似,只在可预测子集位置不同。
主-镜像布局。 TokenDance 使用主-镜像布局压缩每轮次缓存族,如图 8 所示。Diff-Aware Storage 保持一个密集缓存作为主,将每个剩余缓存存储为镜像,仅包含与主的差异。适配器将集体 KV Cache 复用的复用计划转发到存储路径,因此存储已知道哪个请求应成为主以及每个镜像中哪些位置不同。当没有显式复用计划可用时——例如,请求在识别的 All-Gather 轮次之外到达——后端回退到 token 相似度启发式在现有缓存条目中找到可复用主。
图 8:带主-镜像布局的差分感知存储。左:复用后,三个智能体的 KV Cache 仅在 10-20% 位置不同。右:Diff-Aware Storage 存储一个完整主缓存,将每个剩余缓存编码为稀疏差分 (Diff 2, Diff 3)。恢复时,系统从主加其差分即时重建每个镜像。
:::
块稀疏差分表示。 镜像校正存储为块稀疏 K/V 差分。恢复缓存间的差异集中在值因私有上下文或位置依赖 RoPE 旋转而改变的一子集 token 位置。这些不同位置倾向于聚集在对应私有历史段或共享块间边界区域的连续块中。块粒度表示以比细粒度逐元素差分更低的元数据成本捕获这种聚集。它还自然与现代服务引擎使用的块基内存管理对齐,并与第 4.4 节描述的 tile 对齐恢复流水线对齐。
读取时,存储层不急切重建密集镜像张量。相反,它返回一个轻量级镜像对象,保持对主的引用和稀疏差分元数据。这为调用者保留了标准逻辑 KV Cache 抽象,同时延迟物化直到运行时实际需要数据。镜像仅占完整缓存的 10-20%,因此系统立即节省内存,无需支付恢复成本直到执行时间。
此布局的优势取决于提示中共享与私有的比例。All-Gather 模式是自然匹配,因为上一轮的共享输出块主导提示,只有私有历史和轮次任务是每智能体独有的。如果请求分化更强——例如,系统中每个智能体接收共享输出的实质性不同子集——则镜像校正变大,存储收益减少。我们在第 6.3 节量化这一关系。
4.4 融合差分恢复
压缩只有在关键路径上恢复保持低成本才有用。朴素镜像恢复会加载完整主,复制到新缓冲区,并覆盖不同块——为系统从未保留的对象添加额外密集写后读往返。
TokenDance 通过在已经将缓存 KV 数据移动到分页 GPU 内存的分层传输路径内应用稀疏校正来消除这一开销。算法 1 展示了过程。两个 GPU 缓冲区以乒乓方式交替角色:一个从存储接收主块,另一个进行原地校正和写回。每层,路径应用块稀疏差分(行 7),恢复 RoPE 位置(行 10),并将结果写入分页 KV Cache 内存(行 11)——都在普通缓存加载已执行的相同通过内。从不物化单独的密集镜像。
算法 1:一个镜像请求的融合差分恢复
输入: 镜像 M, 槽映射 S, 位置 P^old, P^new, 层数 L
分配乒乓缓冲区 B^load, B^comp
for ℓ = 1 到 L:
加载层 ℓ 的主块到 B^load
同步; 交换 B^load ↔ B^comp
D ← GetDiff(M, ℓ)
if D ≠ ∅:
用 D.values 更新 B^comp.{K,V} 在 D.indices
B^comp.K ← RoPERecover(P^old, P^new, B^comp.K)
使用 S 将 B^comp 写入层 ℓ 的分页 KV Cache
每层唯一额外工作是行 7 的校正,其成本与不同块数量成正比——通常占总量的 10-20%。图 9 展示了块级分发。与主相同的块直接进入注意力。携带差分的块在 SM 内存中校正后才馈送到 FlashAttention。块稀疏格式使每个块做出跳过或校正决策,无需扫描完整缓存,块大小与注意力 tile 大小对齐,因此校正块无需额外重塑。
图 9:块粒度的融合差分恢复。标记"有差分"的块在注意力前在 SM 内存中校正;无差分的块绕过校正路径。
:::
当前原型在注意力前的传输流水线中融合差分,而非在注意力 tile 加载器内。这已消除了密集重建步骤并减少了关键路径上的额外内存流量。更深融合——在注意力 tile 从 HBM 加载到共享内存时应用差分——是自然扩展。
总之,差分感知存储和融合恢复解决了扩展问题的内存侧。存储减少每个额外智能体贡献给内存占用的状态量。融合恢复确保这种压缩在在线执行期间可用而非仅静态时。这是 TokenDance 如何将 All-Gather 模式中固有的结构相似性转化为本地 GPU 上更高活跃智能体容量的方式。
5. 实现
TokenDance 基于 LMCache 和 vLLM 实现。我们添加了约 3K 行 Python 和 500 行 CUDA/C++,跨四个部分:轮次感知段索引、集体 KV Cache 复用、差分感知存储和融合稀疏恢复。
轮次感知段索引。 应用如第 4.1 节所述在逻辑块间插入 <TTSEP> 分隔符。运行时侧,我们用基于段的哈希表替换固定大小块哈希表,在分隔符边界分割提示并独立索引每段。
集体 KV Cache 复用。 vLLM V1 适配器扫描每个调度器步骤的请求,并将每组分发到第 4.2 节描述的集体路径。内部,KV Collector 每个请求创建一个计算生成器和检索生成器,并跨层锁步驱动它们。
差分感知存储。 我们添加了一个包裹正常 LMCache 存储后端的差分感知后端。复用计划可用时,存储路径用它直接选择主并识别镜像位置。无复用计划可用时,后端回退到 token 相似度启发式。主块原样写入。每个镜像块序列化为块稀疏 K/V 差分:后端记录触及的块索引和这些块的 K/V 校正值。当 K 和 V 平面触及相同块时,实现共享块索引列表以减少元数据大小。读取时,后端返回轻量级镜像对象而非密集张量,延迟物化到恢复路径。
融合稀疏恢复。 我们扩展 GPU 连接器的分层乒乓传输路径以识别镜像对象。连接器将主块加载到临时缓冲区,合并当前层的稀疏差分元数据,并在 RoPE 恢复和分页内存写回前原地调用配对 K/V 差分内核。CUDA 扩展提供两个内核:一个用于单个 KV 平面,一个同时更新 K 和 V。当稀疏元数据对齐良好时使用配对内核;否则连接器回退到密集恢复。如第 4.4 节讨论,融合当前在注意力前的传输流水线中发生,而非在注意力 tile 加载器内。
6. 评估
我们评估的主要问题不是 TokenDance 是否加速一轮次,而是能否在相同服务目标下扩展活跃智能体数量。我们围绕五个问题组织评估: (Q1) 系统级扩展收益(第 6.2 节); (Q2) 计算侧收益来源(第 6.3 节); (Q3) 内存侧收益来源(第 6.4 节); (Q4) 融合检索路径是否在关键路径上保留这些收益(第 6.5 节); (Q5) TokenDance 是否保留模型输出保真度(第 6.6 节)。
6.1 设置和指标
我们在 NVIDIA A100 80 GB GPU 上评估 TokenDance。使用两个模型,Qwen2.5-7B 和 Qwen2.5-14B,展示收益随模型大小变化。我们重放来自 GenerativeAgents 和 AgentSociety 的轨迹,两个代表性 All-Gather 模式框架,跨越不同操作区域:GenerativeAgents 使用较短私有历史和每轮较少智能体,AgentSociety 使用较长历史和更多智能体。
我们比较三个跨越现有复用策略空间的基线: (1) vLLM 带前缀缓存,代表标准请求本地复用路径; (2) CacheBlend 无每个请求 KV Cache 恢复(CacheBlend Ordinary Path),使用 CPU 侧 KV Cache 池但无跨前缀复用; (3) CacheBlend 带完整每个请求 KV Cache 恢复,最广泛采用的开源 PIC 方法,执行选择性跨前缀复用但无轮次级共享。
我们的指标直接反映扩展目标。我们从轮次延迟(服务一个智能体轮次的端到端时间)、峰值 KV Cache 占用和恢复开销导出两个容量指标。第一个是在固定延迟目标 ($1500$ ms) 下维持的最大智能体数量。第二个是在给定 QPS 下延迟超过目标前维持的最大智能体数量。这两个视角对应服务系统配置的两种方式:按延迟 SLO 和按吞吐预算。
6.2 主要结果:扩展活跃智能体数量
在相同延迟目标或 QPS 目标下,每个系统可以支持多少智能体?对每个系统,我们扫描智能体数量从 1 到 10 和提供 QPS 从 1 到 16,记录每个操作点的轮次延迟。从这些扫描,我们导出上述两个容量视角。
图 10 展示了四个配置(两个工作负载 × 两个模型)的结果。每个配置显示两个面板:$QPS = 10$ 下的轮次延迟与智能体数量(左,虚线 $1500$ ms SLO 线)和最大支持智能体与 QPS(右)。
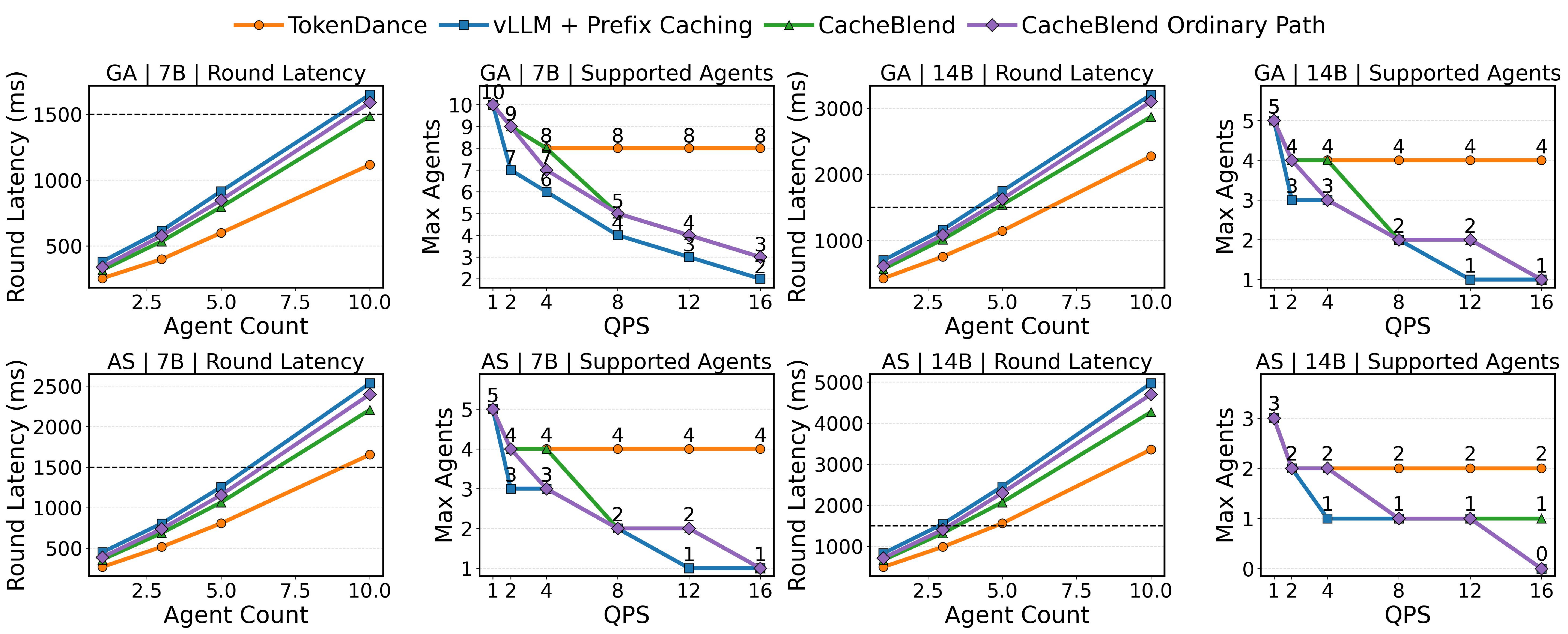
图 10:两个工作负载(GenerativeAgents, AgentSociety)和两个模型(Qwen2.5-7B, Qwen2.5-14B)的扩展容量概览。左面板:$QPS = 10$ 下的轮次延迟与智能体数量;虚线标记 $1500$ ms SLO。右面板:每个 QPS 级别低于 SLO 的最大智能体数量。TokenDance (橙色) 在全 QPS 范围内一致支持比所有基线更多智能体。
:::
TokenDance 在所有配置和智能体数量上一致实现最低轮次延迟。在 GenerativeAgents/Qwen2.5-7B 上,TokenDance 对所有 10 智能体保持轮次延迟低于 SLO,而带前缀缓存的 vLLM 和 CacheBlend Ordinary Path 在 10 智能体时超过 SLO。在 GenerativeAgents/Qwen2.5-14B 上,TokenDance 仍维持所有 10 智能体低于 SLO,而 vLLM 在 7.5 智能体超过,两个 CacheBlend 变体在相似点超过。差距随模型大小增大,因为每个智能体 KV Cache 占用增长,TokenDance 的去重提供比例更大的节省。
支持智能体面板量化扩展收益。在 GenerativeAgents/Qwen2.5-7B 上 $QPS = 16$ 时,TokenDance 支持 8 智能体,而 CacheBlend 降至 4,vLLM 降至 2。在 GenerativeAgents/Qwen2.5-14B 上,TokenDance 在全 QPS 范围内维持 4 智能体,而 vLLM 在 $QPS = 8$ 以上降至 1 智能体。AgentSociety 工作负载(底行)显示相同模式:在 AgentSociety/Qwen2.5-7B 上 $QPS = 4$ 时,TokenDance 支持 4 智能体,而 vLLM 和 CacheBlend Ordinary Path 支持 3。在 AgentSociety/Qwen2.5-14B 上,基线在 $QPS = 4$ 以上几乎无法维持单个智能体,而 TokenDance 在 $QPS = 16$ 仍支持 2 智能体。
两个趋势值得强调。首先,TokenDance 的优势随智能体数量增长。在少量智能体(1-2)时,所有系统表现相似,因为很少有跨智能体冗余可利用。随着智能体数量上升,基线支付线性增长的复用和存储成本,而 TokenDance 跨轮次分摊两者。其次,TokenDance 的优势在 14B 模型上比 7B 模型更明显。这是因为每个智能体 KV Cache 占用随模型大小加倍,使去重在绝对意义上更有价值。这些结果确认核心主张:TokenDance 通过利用 All-Gather 模式增加并发活跃智能体数量,收益随智能体数量和模型大小扩展。
6.3 为什么扩展改善:集体复用计算
集体 KV Cache 复用是否分摊了请求中心方法中随智能体数量增长的复用开销?Q1 中的扩展结果结合计算和内存收益。我们现在通过测量集体 KV Cache 复用如何影响预填充吞吐量随智能体数量增长来隔离计算贡献。
我们重放单个 GenerativeAgents 轮次,同时变化智能体数量(3, 5, 10, 15, 20)和提供 QPS(1, 2, 4, 8, 12, 16)。所有智能体共享上一轮的相同输出块集合,因此跨智能体冗余程度受控。我们测量 TokenDance 集体 KV Cache 复用相对于串行基线的加速,其中每个请求由 PIC 后端独立处理。
图 11 报告结果。y 轴显示集体复用相对于串行路径的加速;值高于 1.0 意味集体复用更快。峰值加速为 $2.57\times$,在 10 智能体和 $QPS = 1$ 时达到。在低 QPS,较大组从分摊获益更多:10 智能体配置达到 $2.57\times$,5 智能体配置在 $QPS = 1$ 达到 $1.31\times$,而 3 智能体配置达到较温和的 $1.17\times$。15 和 20 智能体配置在 $QPS = 1$ 分别达到 $1.61\times$ 和 $1.73\times$;超过 10 智能体,调度开销增长并部分抵消每个请求分摊收益。
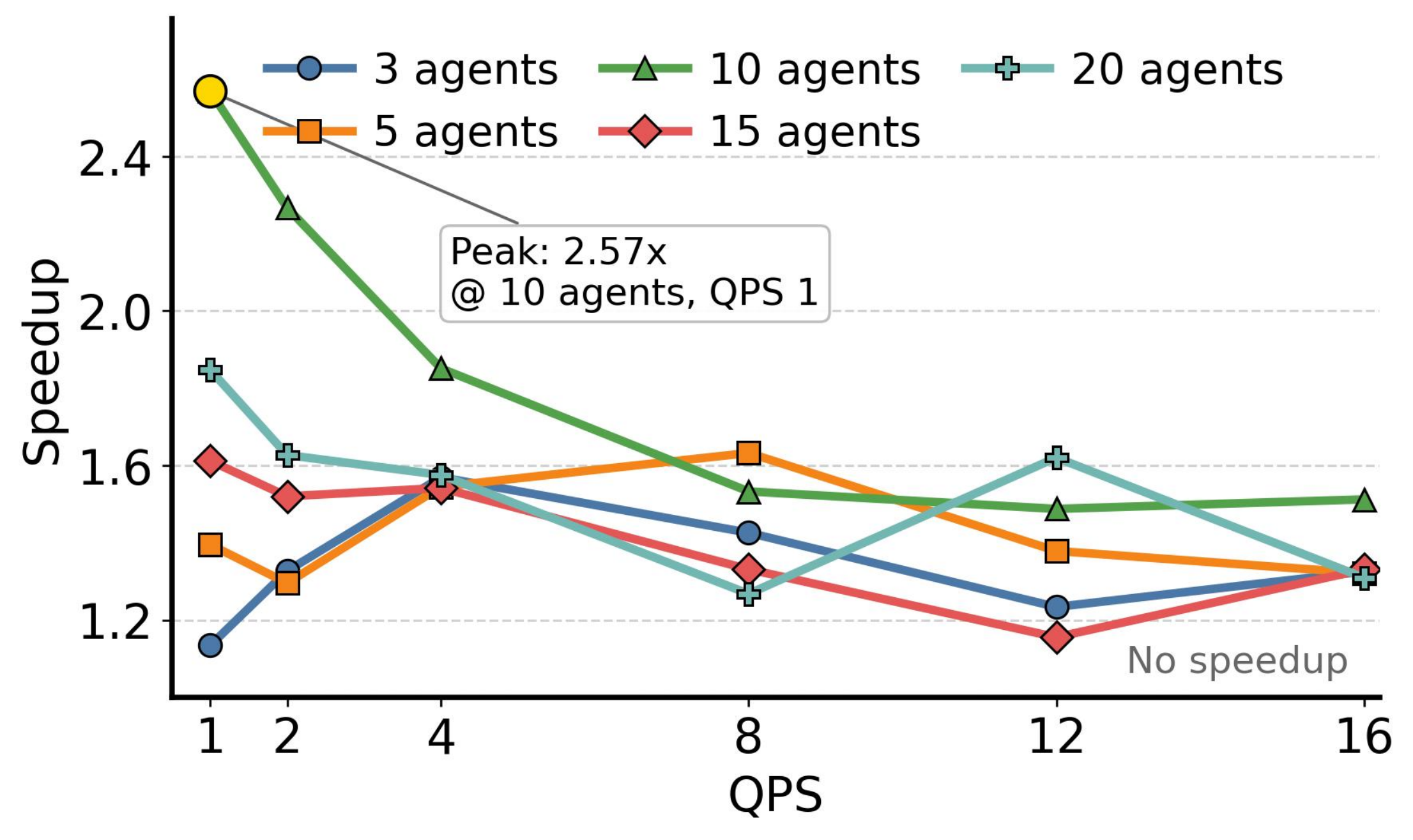
图 11:不同智能体数量(3, 5, 10, 15, 20)和 QPS 级别在 GenerativeAgents 工作负载上集体 KV Cache 复用相对于串行(每个请求)PIC 恢复的加速。峰值加速 $2.57\times$ 发生在 10 智能体和 $QPS = 1$。所有配置在全 QPS 范围内超过 $1.0\times$,确认集体复用一致有益。
:::
两个观察突出。首先,所有智能体数量在全 QPS 范围内达到高于 1.0 的加速,确认集体复用无论组大小都一致有益。收益在低 QPS 最大,系统有时间完全利用集体分组,在高 QPS 最小,GPU 计算饱和限制了边际。其次,随着 QPS 超过 4,加速跨智能体数量收敛到 $1.2$--$1.6\times$ 范围。在高 QPS,GPU 变为计算饱和,瓶颈从冗余复用工作转移到原始计算容量。然而,即使在 $QPS = 16$,集体复用仍提供 $1.3$--$1.5\times$ 加速,直接转化为 Q1 中观察到的更高智能体容量。
关键结论是集体 KV Cache 复用跨轮次分摊 RoPE 和重要位置选择成本。每个请求的复用分析开销在 TokenDance 下随智能体数量亚线性增长,而在请求中心方法如 CacheBlend 下线性增长。这种亚线性扩展是使图 10 中延迟曲线下移并允许更多智能体适应 SLO 的机制。
6.4 为什么扩展改善:KV Cache 占用和存储冗余
主-镜像存储是否显著降低每个智能体轮次的 KV Cache 成本?集体 KV Cache 复用减少计算浪费,但系统仍每个智能体持有一个恢复 KV Cache。如果这些缓存保持密集和重复,内存压力仍将限制活跃智能体数量。我们现在通过刻画恢复缓存间冗余和测量主-镜像布局存储节省来隔离内存贡献。
冗余刻画。 我们为单个 GenerativeAgents 轮次中所有智能体产生恢复 KV Cache,并在块粒度(每块 32 token)将每个镜像与所选主比较。图 12 报告了 7B 和 14B 模型的两个指标。
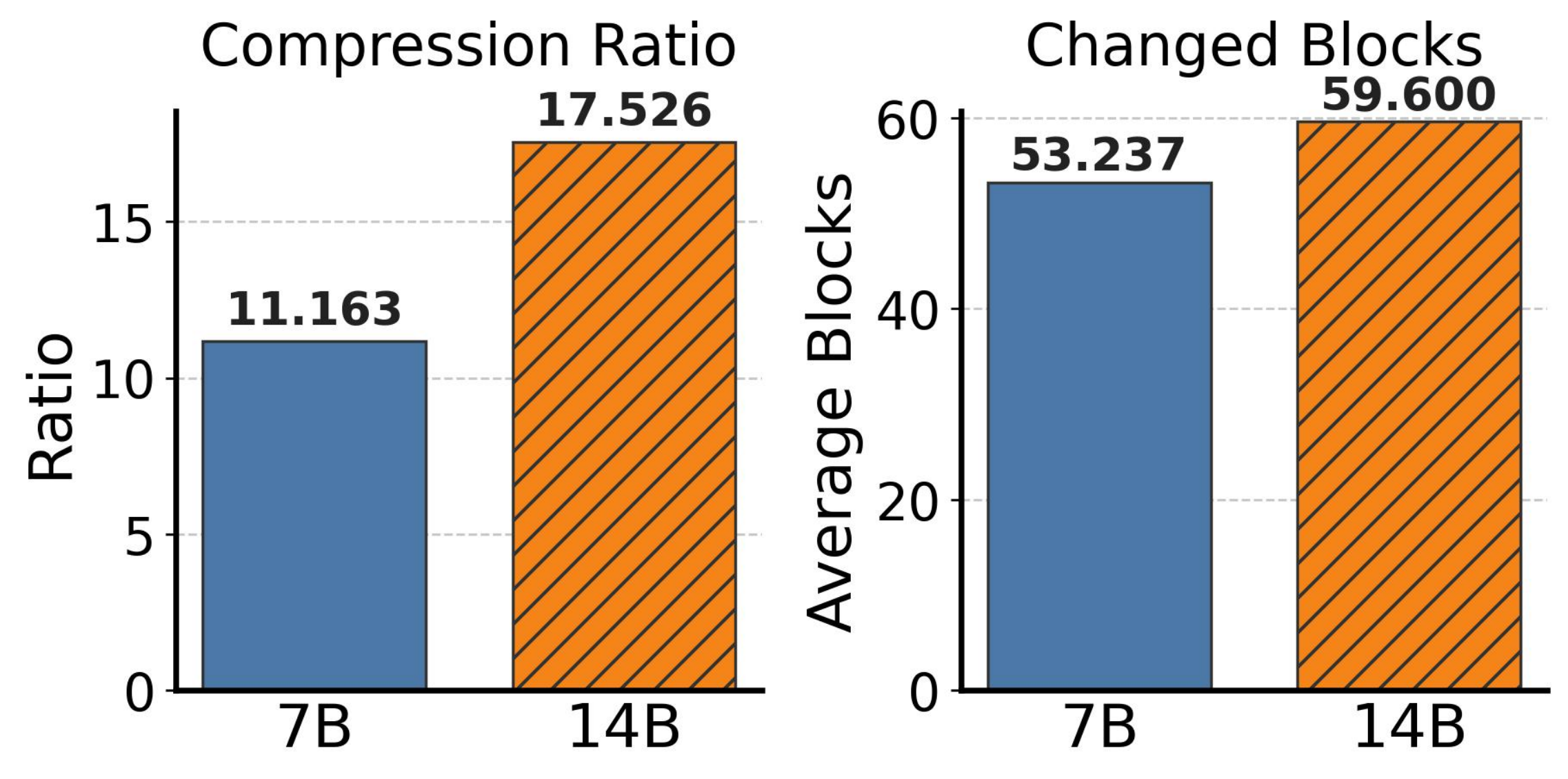
图 12:单个 GenerativeAgents 轮次中智能体间恢复 KV Cache 的冗余刻画。左:压缩比(完整缓存大小除以主加差分大小)。右:镜像与主间平均不同块数(32 token 每块)。14B 模型实现更高压缩,因为每 token 缓存张量更大而不同块数保持相似。
:::
左面板显示压缩比,定义为完整密集 KV Cache 大小与主加差分大小的比率。7B 模型达到 $11.2\times$ 压缩比,意味着差分编码的镜像约为完整缓存大小的 9%。14B 模型达到 $17.5\times$,因为较大模型每 token 产生更长缓存张量而不同块数保持相似。右面板显示每个镜像平均改变块数。7B 模型平均每个镜像改变 53.2 块,14B 模型平均 59.6。这些数字相对于完整缓存的块总数(这些工作负载中典型 500-700 块)很小,确认大部分块与主相同。
14B 模型上更高的压缩比对于扩展意义重大。每个 14B 智能体的完整 KV Cache 约为 7B 智能体缓存的 2 倍大小。通过将镜像压缩到约 6% 的完整大小,TokenDance 有效地从每个智能体存储成本中消除了模型大小惩罚。这解释了为什么 TokenDance 在 14B 模型上比基线的扩展优势更大:存储节省直接转化为更多智能体适应 GPU 内存预算。
隐含容量收益。 以上压缩比转化为具体容量改进。在主-镜像布局下,一轮次中 $N$ 智能体的 KV Cache 成本约为 $1 + (N-1)/R$ 完整缓存,其中 $R$ 是压缩比。对于 7B 模型上 $N = 10$ 智能体($R = 11.2$),这是 $1 + 9/11.2 \approx 1.8$ 完整缓存而非 10,KV Cache 内存减少 $5.6\times$。对于 14B 模型($R = 17.5$),成本为 $1 + 9/17.5 \approx 1.5$ 完整缓存而非 10,减少 $6.7\times$。这种内存减少是允许 TokenDance 在相同 GPU 内存预算内维持更多智能体的机制。
6.5 端到端检索成本
融合检索路径是否在在线服务期间保留存储收益,还是重建延迟消除了压缩收益?朴素恢复路径会通过复制完整主并覆盖不同块来重建密集镜像,在关键路径上添加额外写后读往返。我们比较这种密集恢复方法与 TokenDance 的融合差分路径,后者在分层 GPU 传输流水线内应用稀疏校正,不物化单独密集副本。
图 13 报告了 GenerativeAgents/Qwen2.5-7B 配置上 1, 3, 5, 10 智能体在 QPS 从 1 到 8 的结果。
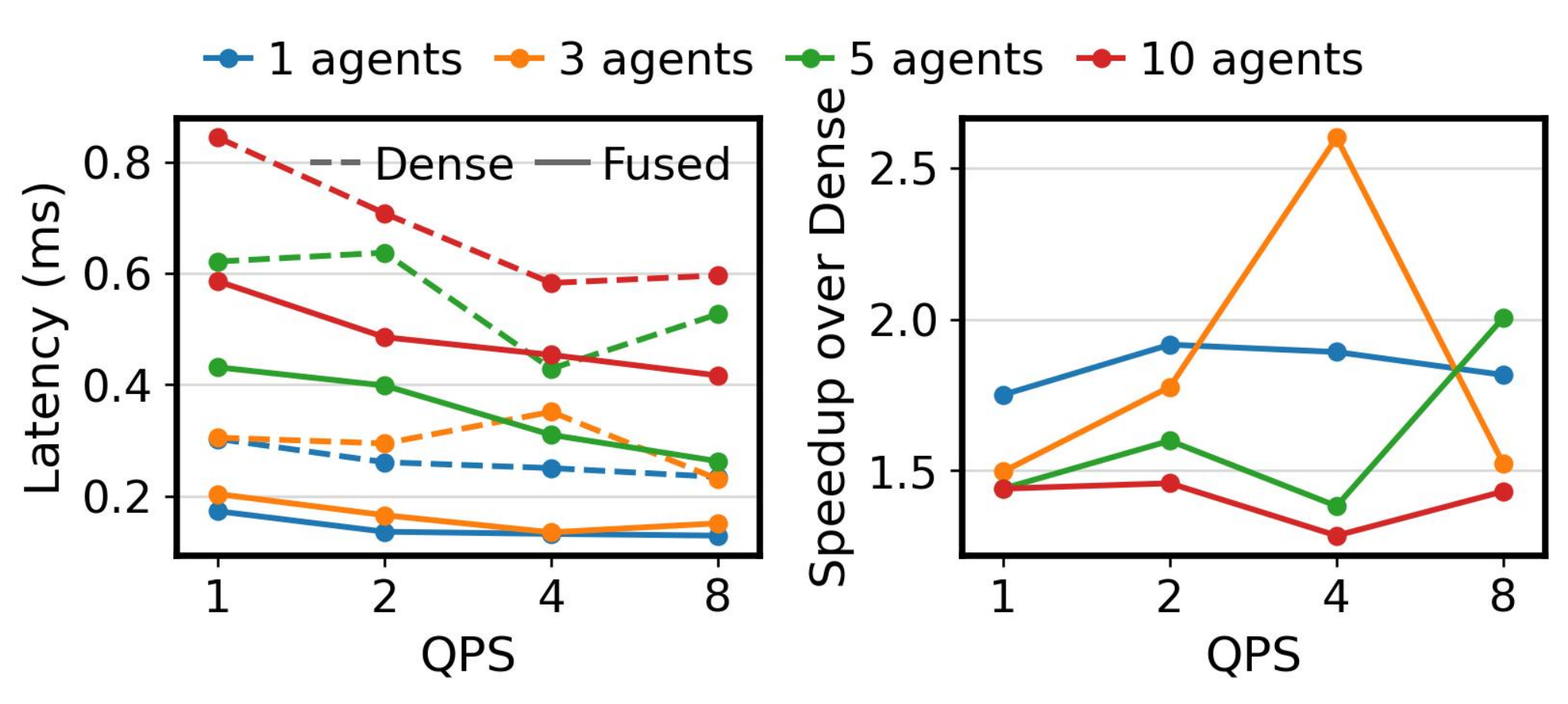
图 13:使用 Qwen2.5-7B 在 GenerativeAgents 上镜像状态重建的延迟分析。左:跨智能体数量和 QPS 级别的密集重建(虚线)和融合差分检索(实线)的绝对恢复延迟。右:融合检索相对于密集恢复的加速。融合检索通过避免单独密集物化步骤一致减少恢复延迟 $1.3$--$2.6\times$。
:::
左面板绘制两种路径的绝对恢复延迟。虚线显示密集恢复;实线显示融合检索。在 10 智能体和 $QPS = 1$ 时,密集恢复每个镜像耗时 $0.59$ ms,而融合检索耗时 $0.43$ ms,减少 27%。在 1 智能体时,融合检索成本 $0.13$--$0.18$ ms,与数百毫秒的整体轮次延迟相比可忽略。随着智能体数量增加,密集和融合路径间的绝对差距扩大,因为融合检索避免了物化越来越大的密集张量。
右面板报告融合检索相对于密集恢复的加速。加速范围为 $1.3\times$ 到 $2.6\times$,取决于智能体数量和 QPS。3 智能体配置在 $QPS = 4$ 达到最高峰值加速 $2.6\times$。1 智能体配置显示全 QPS 范围内一致 $1.8$--$2.0\times$ 加速。在 10 智能体时加速为 $1.3$--$1.5\times$,因为无论重建策略如何恢复流水线都部分带宽受限。全配置中,融合检索一致快于密集恢复,确认 Q3 的存储压缩在在线关键路径上保留。
Q3 和 Q4 的结合完成了内存侧论证。主-镜像存储将每个智能体 KV Cache 占用减少 $11$--$17\times$ (Q3),融合差分检索确保访问压缩表示比重建密集副本添加更少延迟 (Q4)。这两个机制共同使 Q1 中观察到的更高智能体数量成为可能。
6.6 精度影响
TokenDance 的集体复用和压缩存储是否在贪心解码下改变模型输出?从设计上,TokenDance 的集体路径和主-镜像存储产生与底层 PIC 方法逐请求应用相同的恢复 KV Cache;集体分组改变执行顺序但不改变数值结果。在我们的评估中使用 CacheBlend 作为 PIC 后端,因此 TokenDance 产生与逐请求恢复的 CacheBlend 相同的输出。相对于非 PIC 基线(如带前缀缓存的 vLLM)的任何输出差异因此归因于 CacheBlend 的选择性重新计算,而非 TokenDance。
为验证这一点,我们在相同智能体轮次集合上运行 TokenDance 和带前缀缓存的 vLLM,将温度设为 0 以消除采样随机性,并为每个智能体使用相同系统提示和输入历史。对每个场景,我们记录完成仿真轮次数直到首次分化,即至少一个智能体在两个系统下产生不同响应的第一轮次。图 14 报告了跨越两个工作负载八个场景的结果(ID 1-4 来自 GenerativeAgents,ID 5-8 来自 AgentSociety)。
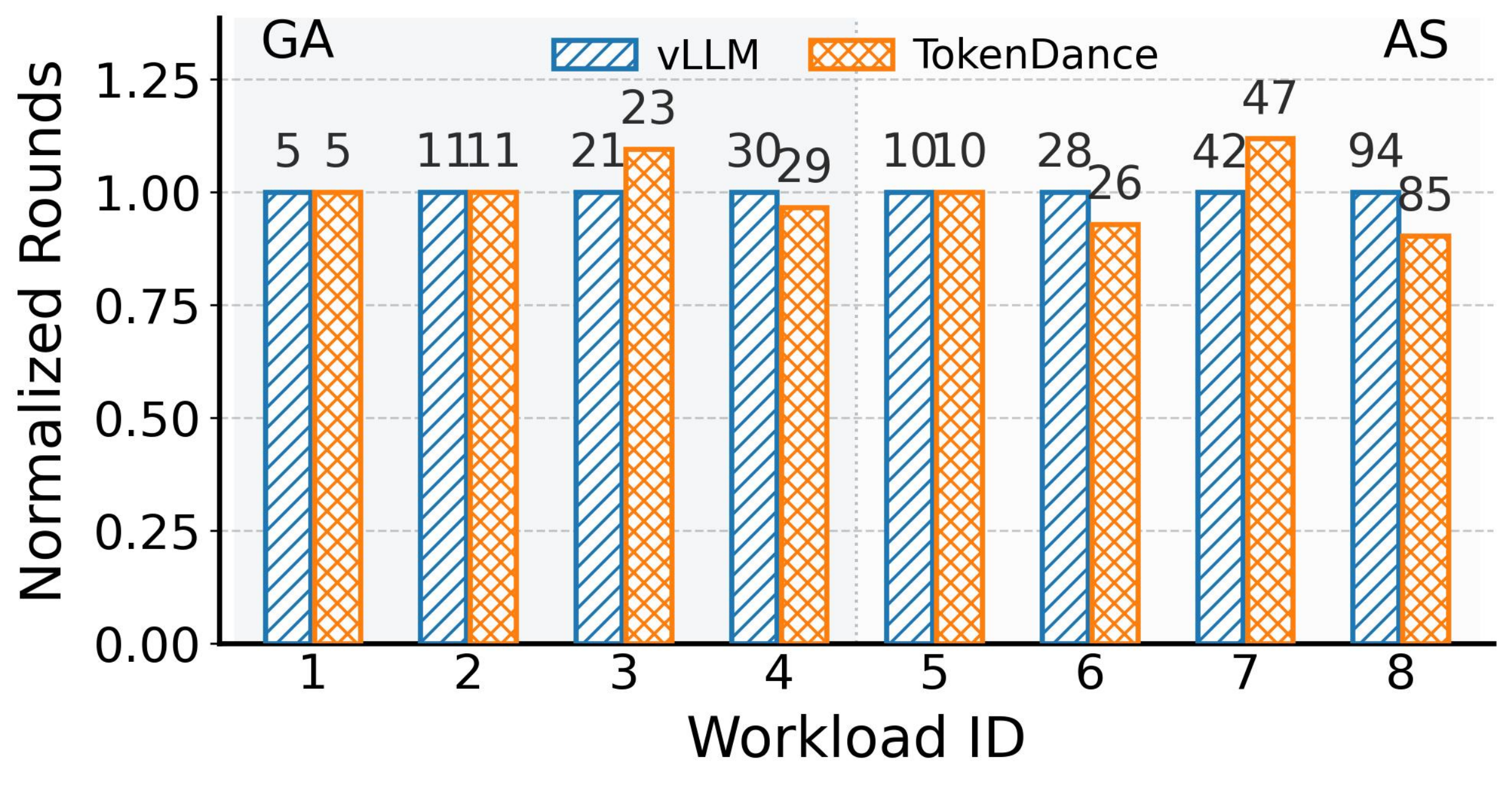
图 14:来自 GenerativeAgents (ID 1-4) 和 AgentSociety (ID 5-8) 八个场景的精度评估。每个条显示 TokenDance 和 vLLM(前缀缓存,温度 = 0)之间首次输出分化前完成的仿真轮次数。相对差异 Δ 在每对上方标注。工作负载 ID 映射:1 = Meet and Greet, 2 = Valentine's Day Party, 3 = Election Discussions, 4 = Winning the Election, 5 = Information Outbreak, 6 = Pre-Landfall Activity, 7 = Hurricane, 8 = Economic Stabilization。三个场景显示零分化;其余差异归因于底层 PIC 方法,而非 TokenDance。
:::
在八个场景中的三个(Meet and Greet、Valentine's Day Party 和 Information Outbreak),两个系统为整个轨迹产生相同输出($\Delta = 0.0\%$)。在其余五个场景中,轮次数差异为 $3.3\%$--$11.9\%$。这些差异出现是因为 CacheBlend 的 PIC 恢复在选择性重新计算位置引入小数值扰动;在贪心解码下,这种扰动最终可能翻转单个 token 选择,然后级联通过后续轮次。这与多智能体仿真的随机性质一致,其中一轮次的小扰动通过后续轮次不可预测地传播。关键结果是 TokenDance 不引入任何底层 PIC 方法已产生之外的额外精度退化。
7. 相关工作
LLM 服务系统。 vLLM、SGLang、Orca 和 Sarathi-Serve 改进了 LLM 推理的批处理、调度和内存管理。这些系统为单个请求优化执行,但不利用 TokenDance 针对的轮次级 KV Cache 冗余。
请求中心 KV Cache 复用。 SGLang 和 vLLM 中的前缀缓存当新请求与存储序列共享精确前缀时复用缓存状态。PromptCache 复用由标记标识的缓存模块,DroidSpeak 跨不同 LLM 共享 KV Cache。EPIC、KVLink 和 KVComm 通过位置校正恢复任意位置复用,CacheBlend 进一步添加选择性重新计算以恢复重要位置精度。所有这些方法一次操作一个请求。TokenDance 不同,将智能体轮次作为复用单元:它跨轮次中所有智能体共享复用工作,并压缩此集体执行产生的 KV Cache 集。
KV Cache 压缩和移动。 HCache、InfiniGen、CacheGen、MoonCake 和 CachedAttention 通过重新计算、卸载、压缩或分解降低长上下文服务成本。这些方法针对单个缓存。TokenDance 相反利用同一轮次兄弟缓存间相似性。主-镜像布局和融合差分路径围绕跨缓存冗余而非单独缓存压缩设计。
KV Cache 逐出和量化。 H2O 和 ScissorHands 通过驱逐低注意力分数 token 减少 KV Cache 内存,StreamingLLM 和 FastGen 对长序列服务只保留固定窗口加少量重要 token。KIVI 和 KVQuant 采用不同路径,将缓存值量化到 2-3 位几乎无精度损失。这些方法压缩单个缓存但不解决跨缓存冗余。TokenDance 正交:它首先移除兄弟缓存间重复数据,然后可以在此基础上应用每个缓存压缩。
注意力内核和稀疏后端。 FlashAttention 展示了注意力性能严重依赖数据移动。FlashInfer 提供高效变长和块稀疏注意力后端。我们的融合差分内核遵循相同数据移动逻辑。它将稀疏差分块与注意力 tile 对齐,使得压缩缓存可以使用而无需额外密集重建通过。
多智能体 LLM 系统。 Parrot、Autellix、Teola、ScaleSim 和 Tokencake 为智能体应用优化调度、预取或执行顺序。LRAgent 通过将缓存分解为共享和适配器特定部分跨多 LoRA 智能体共享 KV Cache。GenerativeAgents、AgentSociety、OpenClaw 和 MoltBook 展示了许多真实智能体工作负载在有共享调度器的显式轮次中运行。这些系统定义或调度智能体应用;TokenDance 为它们都共享的重复收集和分发模式优化 KV Cache 层。
8. 结论
我们提出了 TokenDance,一个通过集体 KV Cache 共享扩展多智能体 LLM 服务的系统。设计遵循两个核心观察:当前复用方法对智能体轮次效率低,即使轮次级 KV Cache 复用后,结果 KV Cache 仍高度可压缩。TokenDance 将这些观察转化为渐进设计,包含集体 KV Cache 复用、主-镜像存储和融合差分检索。在代表性多智能体工作负载上,它比带前缀缓存的 vLLM 减少端到端延迟最多 $2.3\times$,KV Cache 存储减少 94%。
更广泛地,我们的工作论证了通信结构应成为 LLM 服务中的一流概念。All-Gather 模式是一个自然起点,因为它已经出现在许多智能体工作负载中。随着智能体系统继续多样化,其他循环通信模式可能暴露类似机会。通信模式感知服务栈对于使未来多智能体平台大规模高效将很重要。
四、论文简评
创新点
轮次级优化视角:首次将多智能体 LLM 服务的优化单元从单个请求提升到完整轮次,识别并利用 All-Gather 通信模式中的结构性冗余。
集体复用机制:创新性地提出跨智能体共享复用计算,通过一次批处理完成 RoPE 旋转和重要位置选择,避免每个请求重复执行相同分析。
主-镜像存储布局:将兄弟缓存编码为针对单个主副本的块稀疏差分,实现 $11$--$17\times$ 的压缩比,从根本上改变内存成本随智能体数量扩展的方式。
融合差分恢复:在 GPU 传输流水线内应用稀疏校正,避免密集重建步骤,确保存储压缩在关键路径上可用。
局限性
All-Gather 模式依赖:系统优化针对特定通信模式设计,对于不遵循 All-Gather 模式的应用(如异步通信、非共享上下文),收益可能减少或需回退到标准路径。
共享比例敏感:当智能体间共享比例较低(如每个智能体接收不同子集输出)时,镜像校正增大,存储收益减少。论文未给出最小共享阈值。
精度权衡:依赖底层 PIC 方法(如 CacheBlend),可能引入数值扰动导致输出分化,尽管 TokenDance 本身不引入额外退化。
实现复杂度:需要应用侧插入分隔符 token 并修改提示组装逻辑,部署成本较高。目前仅基于 vLLM 实现,跨引擎适配需额外工作。
应用场景
社会仿真平台:如 GenerativeAgents、AgentSociety 等,需要在固定 GPU 内存预算下支持大量并发智能体进行多轮交互仿真。
多智能体编程框架:如 ChatDev、MetaGPT 等,采用同步轮次执行模式进行协作编程、任务分解等。
大规模智能体部署:生产环境中需要从数个智能体扩展到数十甚至数百个的场景,内存预算是主要瓶颈。
多轮对话系统:采用中央调度器收集和分发上下文的对话系统,可受益于轮次级 KV Cache 共享。
可改进方向
通信模式扩展:识别并优化其他常见多智能体通信模式(如异步消息传递、分层调度等),扩展适用场景。
动态分组策略:探索跨轮次的请求分组优化,处理智能体加入/退出、动态负载变化等场景。
跨引擎适配:扩展到 SGLang、TensorRT-LLM 等主流服务引擎,降低部署门槛。
自适应压缩策略:根据实时共享比例动态选择主-镜像 vs 密集存储,避免低共享场景的过度压缩开销。
更深融合优化:将差分校正进一步融合到注意力 tile 加载器内,减少 HBM 到共享内存的数据移动。